少し前に一部界隈で話題になった記事
Linuxのコードをたった30行修正するだけでデータセンターの電力消費量を最大30%削減可能、実際にLinux 6.13から反映される
今回は記事の大元となる論文を読んで、実際にどうなのか解説します。
Kernel vs. User-Level Networking: Don’t Throw Out the Stack with the Interrupts
コミットについてはこちらから
Suspend IRQs during application busy periods
[PATCH net-next v7 0/6] Suspend IRQs during application busy periods
目次
結論
- 論文内で「データセンターの電力消費量が30%削減可能」とは言っていない
- 高負荷なネットワーク処理において、30%程度のスループット向上が見込める
- これらはアプリケーションへのIRQ(割り込み)を抑制することで実現できる
gigazineが参照した以下の記事において、研究者らが「電力消費量を30%削減可能」と発言したとされていますが、論文内にそのような記述は存在しませんでした。
Changing Linux code could cut data center energy use by 30%, researchers claim
記者が論文内の「30%の性能向上」を「30%の電力削減」と勘違いしたか、記事タイトルに強いインパクトを持たせるために改変したか、研究者らが別の根拠を元に発言したかのいずれかです。
(サーバーは多数の要素によって成り立っており、ネットワーク処理の性能が30%上がったからと言って消費電力が30%下がるわけではありません)
とはいえ論文自体は非常に興味深い内容となっていますので、以下では論文の内容について解説していきます。
論文について
前提知識: ユーザーレベルネットワーク
従来、ネットワークスタックはカーネル内で処理されていました。
このとき、非同期割り込み(IRQ)やユーザー空間とカーネル空間への往復(コンテキスト)などによるオーバーヘッドが性能向上の妨げとなっていました。
ユーザーレベルネットワークは「カーネルバイパス」や「専用のポーリング処理」を用いることで、オーバーヘッドを回避し効率的なネットワーク処理を実現するために開発されました。
代表的なものとしては
・DPDK(Data Plane Development Kit)
ユーザーレベルで高速なパケット処理を実現するためのライブラリやドライバ群
・F-Stack
FreeBSDのネットワークスタックをユーザーレベルに移植し、カーネルバイパスを実現
特にDPDKが出て以降は、多くのユーザーレベルネットワークが実装されました。
パフォーマンスモデルの定義
この論文ではパフォーマンスの評価指標として以下を使用しています。
QPT (Queries Per Time)
1秒あたりに処理できるクエリの数です。
スループットと呼ばれ、一般的には「性能」とも呼ばれます。
CPT (Cycles Per Time)
1秒あたりに実行されるCPUサイクルの数です。
いわゆる「CPU周波数」ですが、この実験では動作クロックを固定するので固定値として扱います。
IPC (Instructions Per Cycle)
CPUの1サイクルで実行される命令の数です。
主にメモリアクセスによるストールや、投機的実行の成功率で変動します。
CPUから見たメモリは非常に低速であり、その間には緩衝用のキャッシュが何段も存在します。
このキャッシュに乗っていないデータを取ろうとするとメモリにアクセスする羽目になり、その間は命令の実行がブロックされます。これがメモリアクセスによるストールです。
一方で、現代のCPUには投機的実行と呼ばれる仕組みがあります。
これは未来に実行される【かもしれない】命令をCPUが先に実行してしまうのです。
本当に実行された場合は結果のみを提出し、実行されなかったら結果を破棄します。
これの成功率もIPCには大きく影響しています。
IPQ (Instructions Per Query)
1クエリあたりに実行される命令の数です。
基本的にはコンパイル時に決定され、アルゴリズムなどの改善によって減少します。
まとめ
これらの指標を用いると、システムのスループット(QPT)は、以下の式で表されます。
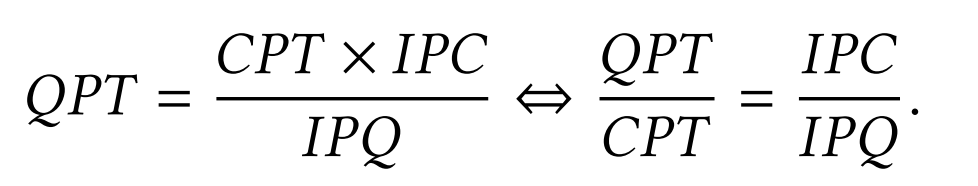
CPT(CPU周波数)が固定値とすると、IPCを上げるかIPQを下げるかしかありません。
予備実験
nginxとmemcachedを用いて、デフォルト設定(Vanilla)とF-Stackの性能を評価しています。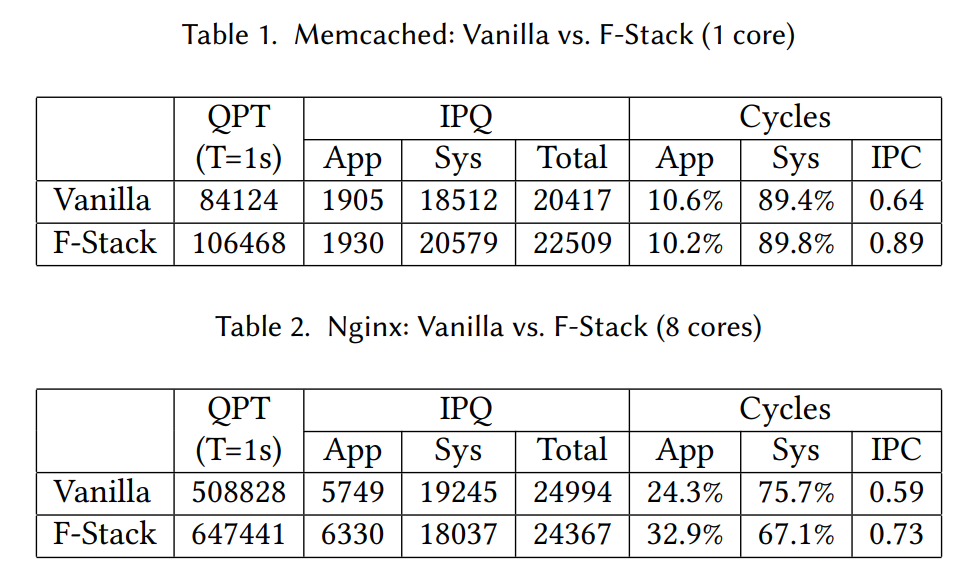
Memcachedの約10%のIPQ増加に関してはshimという機能が原因だろうと3.2.1節で述べられています。
一方でIPCは39%向上しており、結果として大幅な全体パフォーマンスの改善につながっています。
NginxについてもIPQはほぼ同じですがIPCの向上により全体で27%の性能向上があるようです。
また、NUMAによる性能劣化の調査も行われています。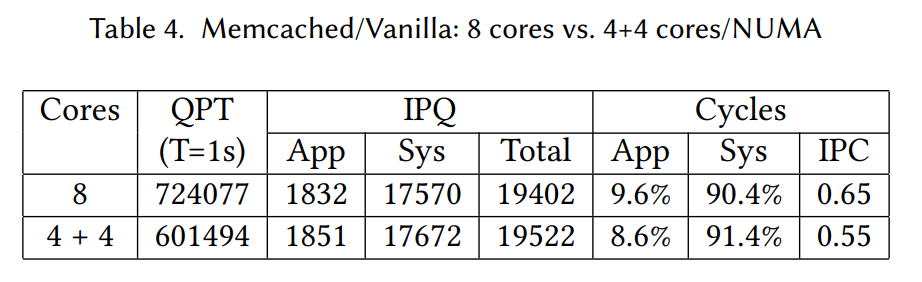
1CPU(8コア)と2CPU(4+4コア)では、IPCの低下により17%の性能劣化が見られました。
仮説
予備実験の結果から性能向上の内訳を分析すると、従来考えられていた「カーネルバイパスによって1クエリあたりに必要な命令数(IPQ)が減少する」という効果よりも、実際には「CPUのIPCの向上」に起因することが明らかになりました。
そしてIPCは先述した通り、投機的実行の成功率やメモリアクセス時のストールなど、CPUパイプラインの効率に強く依存しています。
筆者は、割り込み(IRQ)の発生が、CPUの現在実行中のアプリケーション処理を中断し、カーネルの割り込み処理関数に制御を移すため、パイプラインが大幅に乱れ、IPCが劣化することが主な原因であると考えています。
つまりユーザーレベルネットワークは、ユーザーレベルで処理を行ったことにより、IRQの発生が抑えられた結果としてCPUのIPCが向上し、その副次的な効果として全体の性能が上がっていると推測しています。
本実験ではこの仮説を検証しています。
本実験
手法1: デフォルト (IRQ Balancing)
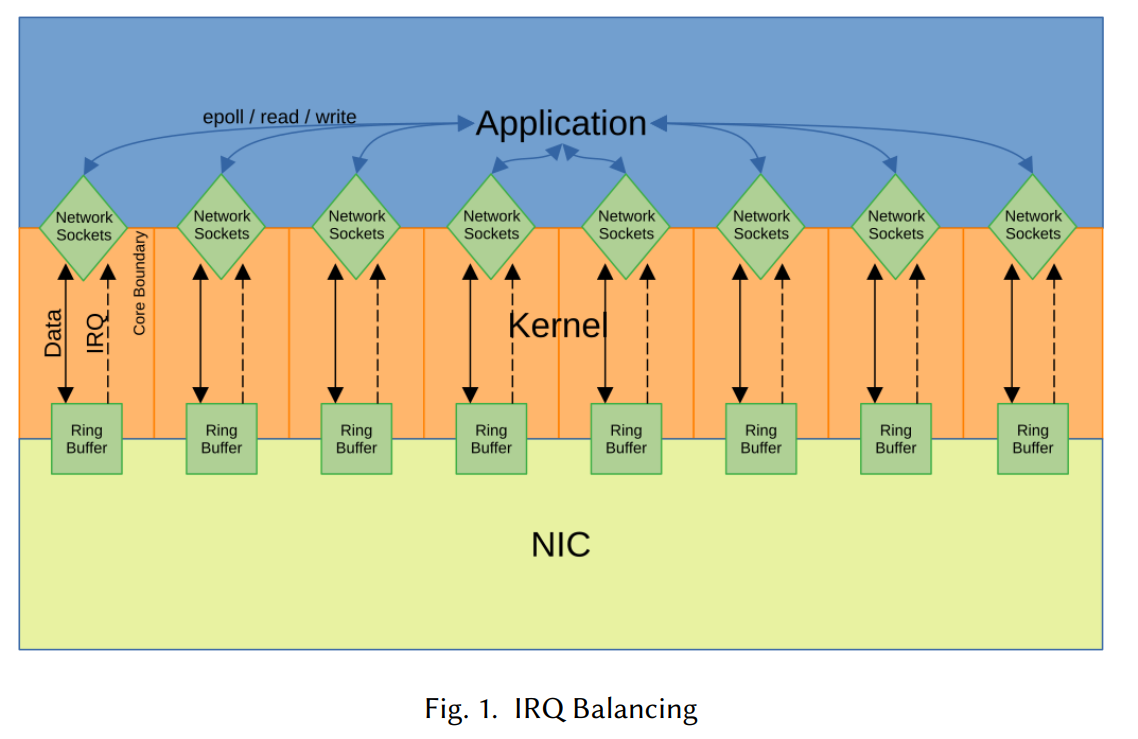
Linuxカーネルの標準的な設定です。
アプリがNコア上で展開される場合、N個のRX/TXキューを設定し各コアに割り当てます。
NICは非同期にIRQ(割り込み)を発行し、ネットワーク処理はカーネル内(softirq)で行われます。
その後、別のIRQによりアプリケーションにデータの準備が通知されます。
分散により各コアに過剰な負荷はかかりませんが、アプリケーションと割り込み処理が非同期に競合するため、効率的な整合性が得られない可能性があります。
手法2: IRQ Packing
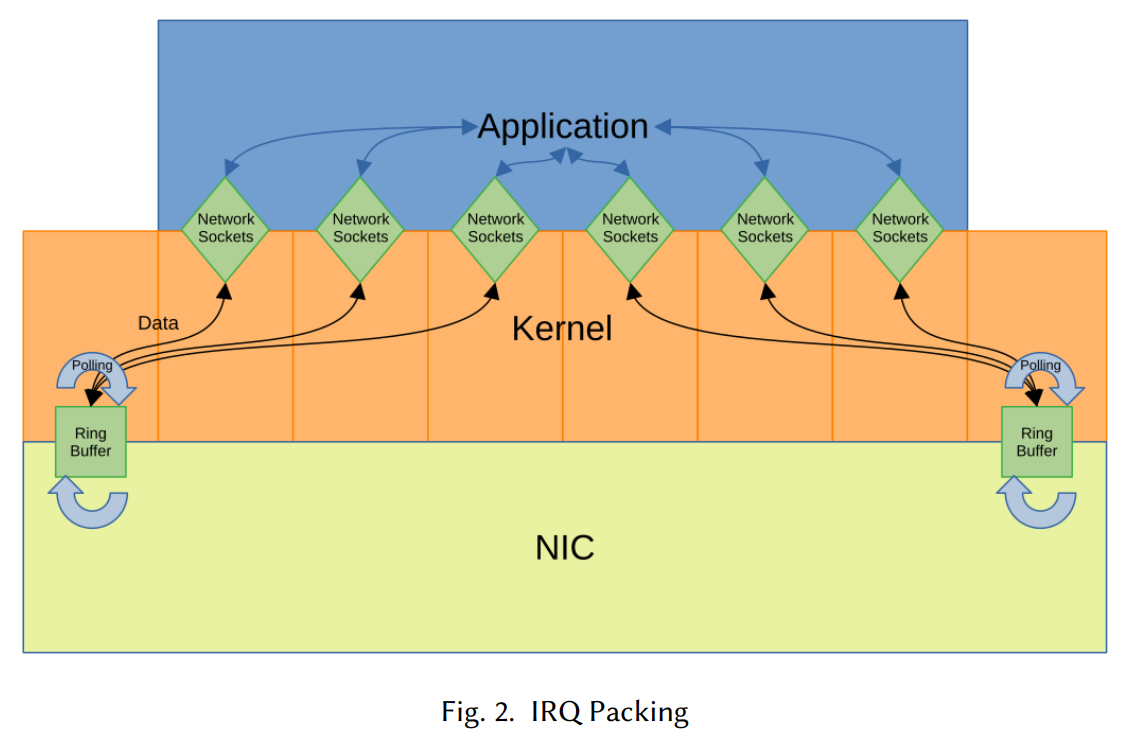
割り込み処理を特定の少数コアに集約し、その他のコアはアプリケーション処理専用に割り当てます。
CPUキャッシュなど空間的整合性は必ずしも向上しませんが、IRQを集約することによりアプリケーション処理が中断されにくくなります。
しかし、ネットワーク通信量は変動するのに対してCPU割当は固定なので、割り込み専用コアの使用率が下がるほど(リソースを無駄にしてるので)全体のパフォーマンスが下がります。
割り込み専用コアは常に使用率100%の状態が理想ですが、なかなか難しいのが現状です。
手法3: IRQ Suppression (IRQ抑制)
NICのIRQ抑制機能を利用し、割り込みの発生を遅延させることで一定期間のパケットをまとめて取得する方法です。NICに対しての変更であり、ethtoolを用いて設定できるので簡単です。
設定数値を高くすることで、割り込み発生回数を大幅に削減することができますが、動的なワークロードに対しては適用が難しいです。また、レイテンシの悪化も懸念点です。
手法4: Kernel Polling (提案手法)
前提知識: ネットワークポーリング
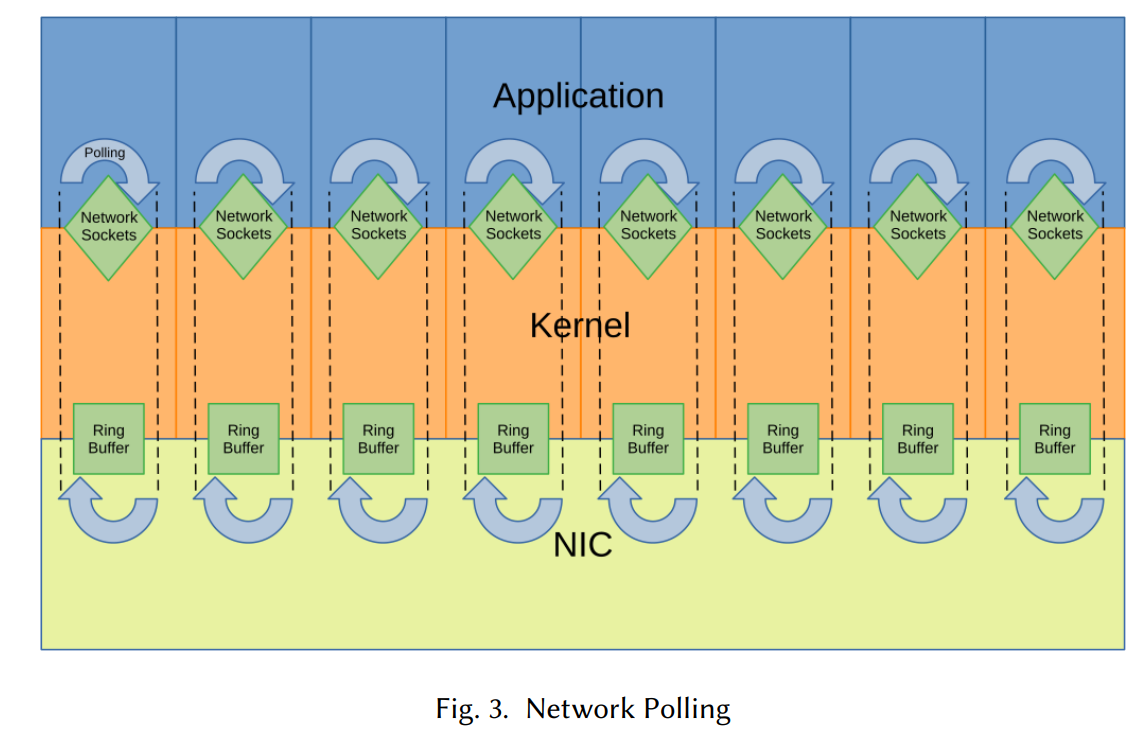
Linuxでは sysctl net.core.busy_poll を利用してポーリングの設定が可能です。
これを設定するとアプリケーションは select(), poll(), epoll_wait()などを利用し、即座にイベントが得られない場合でも設定された数値の間はNICのポーリングを行います。
ポーリング期間中にパケットが受信されれば、ネットワーク処理は同じ実行パス内で行われ、ユーザーレベルネットワーキングに類似した性能向上が見込めます。
カーネルはポーリング期間中は割り込みを抑制しますが、ループから戻るとすぐに割り込みは再有効化されます。そのため、アプリケーションがポーリングによって取得したデータを処理している間にも、IRQは到着し続け、アプリケーションの実行に影響を及ぼします。
前提知識: NAPI (New API)
そんな雑な名前でいいのか
NAPIは従来の割り込み駆動方式とポーリング方式を組み合わせたハイブリッドな手法です。
挙動としては、
1. パケット受信時、まずソフトウェア割り込みを発生させる。
2. 受信処理をしている間は、割り込みを禁止する。
3. 受信処理ではNICのキューをポーリングする。
ポーリング処理とNAPIについては、こちらの記事が非常に参考になります。
新Linuxカーネル解読室 – パケット受信処理 ~Ethernetドライバ ポーリング処理編~
改善案
そこで、筆者らはカーネルのポーリングシステムに30行ほどの変更を加えました。
これがタイトルにある「たったの30行修正するだけで」の部分です。
変更点としては
・イベントが存在する間は割り込みをマスク(11行目)して連続的にポーリングを行い、割り込みによるIPCの低下を防ぐ。
・イベントが見つからなくなった時点で割り込みを再有効化(18行目)し、待機状態に入る。
・イベント取得時にNAPI IDのチェックを行い、前回と異なるソースからイベントが到着した場合は、前回のソースからの割り込みを有効化(8行目)して新しいソースの割り込みをマスクする(18行目)
パッチはこちらから確認できます。
[PATCH net-next v7 0/6] Suspend IRQs during application busy periods
実験結果
スループット
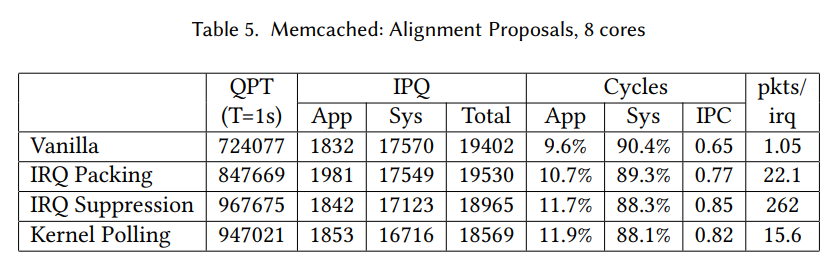
デフォルト(Vanilla)に比べ、各手法は大幅にスループットが向上しました。
IRQ Packingがデフォルト以外の手法と比べてスループットが低いのは、割り込み専用コアを設けているため、そこがボトルネックになっていると考えられています。
IRQ Suppression(IRQ抑制)についてはかなり攻めた値を取っていて、論文によると(rx-usecs 65534、rx-frames 65534、tx-usecs 1024、tx-frames 256)
に設定しているようです。割り込み一回で平均262個のパケットを処理しているわけですから凄い。
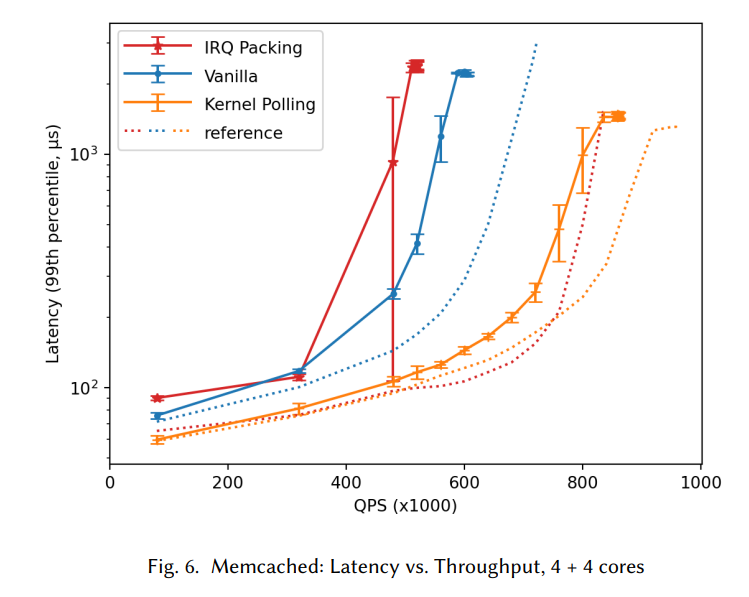
レイテンシ
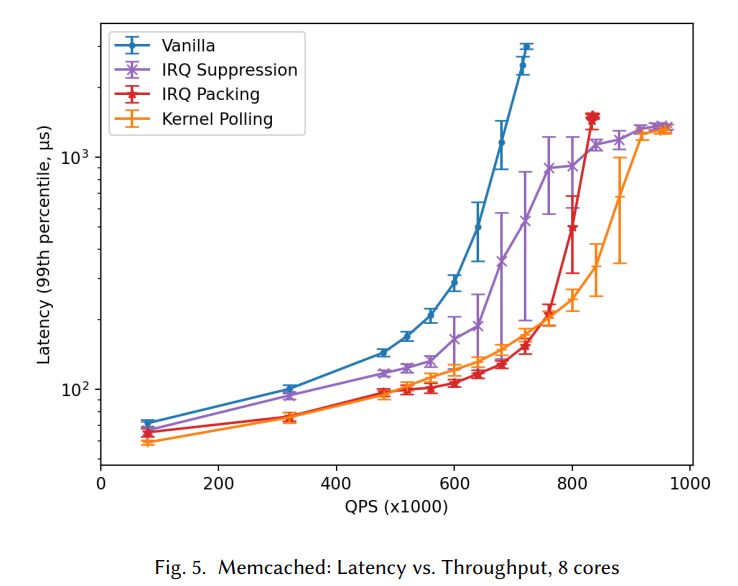
横軸にスループット(QPS)、縦軸にレイテンシと、その99パーセンタイルを取っています。
これを見ると、先ほどスループットが高かったIRQ Suppressionについては、負荷が低いタイミングでもレイテンシに大きなバラツキがあるのを確認できます。また、平均的にもレイテンシが高いです。
割り込みを無条件で一定期間マスクしてしまうので、当然の結果ではありますね。
NUMAによる性能劣化
次にNUMAによる性能劣化について。
デフォルト(Vanilla)と提案手法(Kernel Polling)については同じ程度の劣化で済んでいますが、IRQ Packingは大幅に性能劣化しています。
論文では割り込みの2コアと、アプリケーションの6コアを別のNUMAノードで動かしたとあったので、NUMAドメイン間での通信が大きなコストになったと考えられます。
これについては、ちょっと恣意的なグラフだと思います。
各NUMAノードについて、割り込み:アプリケーション=1:3にしたらIRQ Packingはもう少し性能劣化を抑えられそうですが、論文ではこれについて言及はありませんでした。
まとめ
従来のカーネルネットワークスタックにおける非同期割り込み処理が、実際のパフォーマンスに大きなオーバーヘッドを与えていることがわかりました。
ユーザーレベルネットワークの性能向上の内訳を調査すると、1クエリあたりの命令数(IPQ)の削減ではなく、CPUのIPCが向上していることが確認されました。
IPCの向上は、割り込み発生によるCPUパイプラインの乱れが抑えられた結果であり、ユーザーレベルネットワーキングの本来の狙いとは異なる副次的な効果であると考えられます。
割り込みが発生すると、CPUは現在のアプリケーション処理を中断してカーネルの割り込み処理に切り替わるため、パイプラインが大きく乱れ、結果としてIPCが低下します。
ユーザーレベルで処理する、もしくはKernel Pollingのような方式で割り込みの再有効化を遅らせることでCPUのIPCが向上し、全体のスループットが増加することが実験結果から確認されました。
筆者らの提案する手法は、従来の割り込み処理を自動的に制御し、アプリケーションが忙しく動作している間は割り込みを抑制することで、高い性能向上(UMAで約30%、NUMAで約45%)と低いレイテンシを実現しました。
また、ユーザーレベルネットワーキングの利点を享受しつつ、専用コアの予約やスレッド固定といった制約がなく、従来のカーネルスタックのままで実装可能であるという利点があります。
この変更はLinux 6.13から適応される予定です。
感想
CDNのような、ネットワーク処理をとにかく大量に捌きまくるサーバーにとって大きな変更だと思います。
もっともCloudFlareをはじめとした大手CDNはゴリゴリにチューニングしたカーネルを使ってるだろうから、恩恵が30%もあるかと言われるとだいぶ怪しそうではありますが…