今回は Linux 6.14で導入される Uncached Buffered I/O について解説します。
従来のBuffered I/OとDirect I/Oの利点を組み合わせた方法で、NVMeドライブなどの高速なストレージデバイスで有効なI/O方式となっています。
目次
まとめ
- ストレージの高速化によりページキャッシュの回収がボトルネックになってきた
- Direct I/O と Bufferd I/O の良いとこ取りをする Uncached Buffered I/O を提案
- Linux 6.14 で追加予定。最大で65%のI/O性能向上と、CPU使用率を50%削減可能
本編
前提知識
Uncached Buffered I/Oを理解するために、まずはDirect I/O, Buffered I/O, 同期I/O, 非同期I/Oといった基本的な情報について解説します。
Buffered I/O
LinuxのデフォルトのI/Oモードです。
カーネルは、読み書き操作をページキャッシュと呼ばれるメモリ領域にキャッシュします。
これにより、同じデータへの複数回のアクセスを高速化し、I/O操作の回数を減らすことでパフォーマンスを向上させることができます。
Buffered I/Oでは、書き込みは後でディスクに行われますが、バッファキャッシュがいっぱいになったときや、fsync が呼び出されたときにもトリガーされることがあります。
Direct I/O
アプリケーションが O_DIRECT フラグを指定してファイルを開くことで、カーネルのページキャッシュをバイパスし、ストレージデバイスと直接データのやり取りを行います。
DBのようにアプリケーション側でバッファリングを行う場合に有効です。
また、Direct I/Oを使用するには I/O 操作が特定のメモリアドレスで開始され、サイズがブロックサイズの倍数であるなど、アライメントの制約を満たす必要があります。
Buffered I/O との違いを図にするとこんな感じ。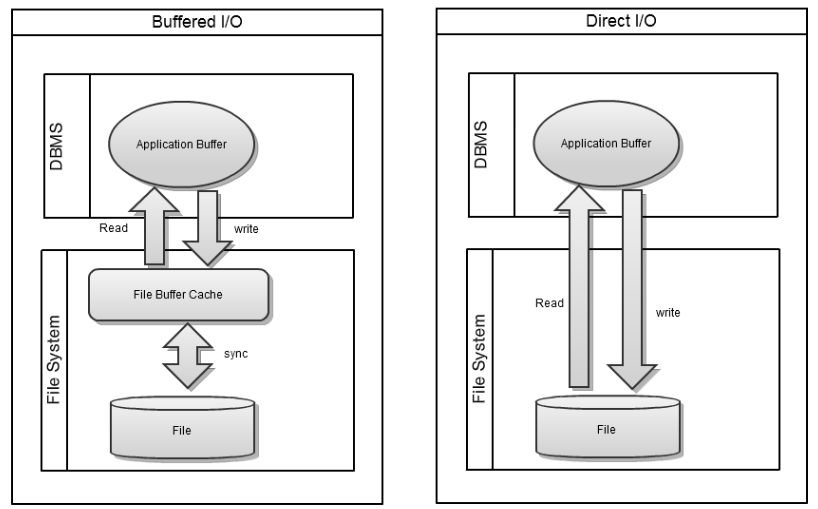
参考: ALTIBASE, “5. Disk I/O Optimization”
Buffered I/Oは、read-ahead や write-back などの最適化により、メモリアクセスに近いパフォーマンスを実現できます。
しかし、大容量ファイルへのシーケンシャルなI/OではDirect I/Oの方がCPUオーバーヘッドとメモリ使用量を削減できる場合があります 。
同期 I/O と 非同期 I/O
I/O操作は、同期と非同期の2つの方法で実行できます。
・同期I/O: 完了するまで、アプリケーションは処理をブロックされます。
・非同期I/O: バックグラウンドで実行し、アプリケーションはI/Oの完了を待たずに処理を続行できます。
AIO (Asynchronous I/O) や io_uring などの非同期I/Oは、I/Oの完了を待つ間にCPUを他の処理に利用できるため、システム全体の性能向上に貢献します。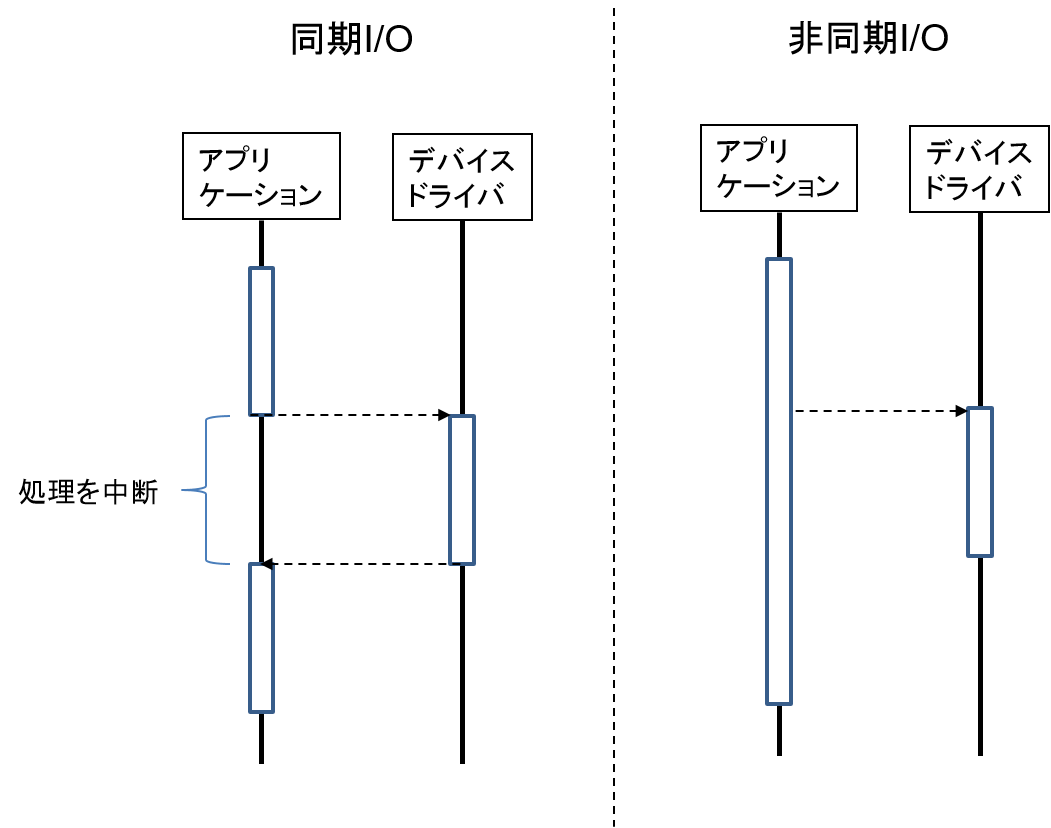
参考:電気通信主任技術者 過去問解説, “28年 第1回「データ通信」”
Uncached Buffered I/O について
ここからが本編です。
Uncached Buffered I/O は Buffered I/O の一種ですがページキャッシュにデータを保持しません。
データを処理した後すぐにページキャッシュは廃棄されます。
データがキャッシュに蓄積されることはなく、より効率的にメモリ管理を行います。
具体的には、
読み込み操作ではデータがページキャッシュに読み込まれた後、すぐにキャッシュから削除されます。書き込み操作ではデータはページキャッシュを介して書き込まれますが、書き込みが完了するとすぐにキャッシュから削除されます 。
従来のBuffered I/Oではページキャッシュが一杯になると、カーネルはLRU (Least Recently Used) などのアルゴリズムに基づいてキャッシュからデータを削除する必要がありました。
そしてこの処理は、パフォーマンスの低下やI/O時間の変動を引き起こす可能性がありました。
例えば32台のドライブを搭載したテスト環境で、従来のBuffered I/Oで読み込みを行うと、ページキャッシュがいっぱいになった時点でスループットが低下し不安定になることが確認されています 。
[PATCH 08/12] mm/filemap: add read support for RWF_DONTCACHE
As an example, on a test box with 32 drives, reading them with buffered IO looks as follows:
Reading bs 65536, uncached 0
1s: 145945MB/sec
2s: 158067MB/sec
3s: 157007MB/sec
4s: 148622MB/sec
5s: 118824MB/sec
6s: 70494MB/sec
7s: 41754MB/sec
8s: 90811MB/sec
9s: 92204MB/sec
10s: 95178MB/sec
11s: 95488MB/sec
12s: 95552MB/sec
13s: 96275MB/sec
where it's quite easy to see where the page cache filled up, and performance went from good to erratic, and finally settles at a much lower rate. Looking at top while this is ongoing, we see:
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
7535 root 20 0 267004 0 0 S 3199 0.0 8:40.65 uncached
3326 root 20 0 0 0 0 R 100.0 0.0 0:16.40 kswapd4
3327 root 20 0 0 0 0 R 100.0 0.0 0:17.22 kswapd5
3328 root 20 0 0 0 0 R 100.0 0.0 0:13.29 kswapd6
3332 root 20 0 0 0 0 R 100.0 0.0 0:11.11 kswapd10
3339 root 20 0 0 0 0 R 100.0 0.0 0:16.25 kswapd17
3348 root 20 0 0 0 0 R 100.0 0.0 0:16.40 kswapd26
3343 root 20 0 0 0 0 R 100.0 0.0 0:16.30 kswapd21
3344 root 20 0 0 0 0 R 100.0 0.0 0:11.92 kswapd22
3349 root 20 0 0 0 0 R 100.0 0.0 0:16.28 kswapd27
3352 root 20 0 0 0 0 R 99.7 0.0 0:11.89 kswapd30
3353 root 20 0 0 0 0 R 96.7 0.0 0:16.04 kswapd31
3329 root 20 0 0 0 0 R 96.4 0.0 0:11.41 kswapd7
3345 root 20 0 0 0 0 R 96.4 0.0 0:13.40 kswapd23
3330 root 20 0 0 0 0 S 91.1 0.0 0:08.28 kswapd8
3350 root 20 0 0 0 0 S 86.8 0.0 0:11.13 kswapd28
3325 root 20 0 0 0 0 S 76.3 0.0 0:07.43 kswapd3
3341 root 20 0 0 0 0 S 74.7 0.0 0:08.85 kswapd19
3334 root 20 0 0 0 0 S 71.7 0.0 0:10.04 kswapd12
3351 root 20 0 0 0 0 R 60.5 0.0 0:09.59 kswapd29
3323 root 20 0 0 0 0 R 57.6 0.0 0:11.50 kswapd1
[...]
which is just showing a partial list of the 32 kswapd threads that are running mostly full tilt, burning ~28 full CPU cores.これはページキャッシュ管理の部分がボトルネックになっているためです。
(topで確認すると kswapd がCPU使用率100%に張り付いているのがわかります)
昔はストレージ = HDDで超低速なデバイスだったので可能な限りメモリ上にキャッシュを持とうとしていましたが、最近はストレージが高速化しすぎて逆にページキャッシュがボトルネックになるとは…時代を感じます。
このような性能劣化はNVMeディスクなど高速なストレージに対してシーケンシャルな読み書きを発行する際に、最もよく確認されるようです。
一度使ったキャッシュが再利用される前に廃棄されることが多いためですね。
Uncached Buffered I/Oではデータがキャッシュに保持されないため、このような問題が発生しません 。Uncached Buffered I/Oは、Buffered I/Oのページキャッシュの予測不可能性と、Direct I/Oのアライメント制約および同期的な性質の両方の制限に対処します。
Uncached Buffered I/Oは、RWF_UNCACHED フラグを指定することで有効になります。 preadv2() や pwritev2() などのシステムコール、または io_uring を使用して、このフラグを設定することができます。
Uncached Buffered I/O のパッチ解説
本編その2です。
[PATCHSET v8 0/12] Uncached buffered IO
こちらのパッチセットをベースに、Linuxソースコードレベルで解説を行います。
[PATCHSET v8 0/12] Uncached buffered IO
翻訳文の一部を載せておきます。
なぜこれを行う必要があるのか?一言で言えば、デバイスの速度はますます速くなっているのに対し、リクレイム(メモリ回収)はそうではないからです。
通常のバッファ付きIOは非常に予測不可能であり、リクレイム側で多くのリソースを消費する可能性があります。これが、人々がO_DIRECTを回避策として使用する理由につながっていますが、O_DIRECTにはサイズ、オフセット、IOの長さに制約があります。また、本質的に同期処理であり、今では非同期IOも必要になっています。非同期IOについては、優れた選択肢が利用可能であるため、必ずしも大きな問題ではありませんが、キャッシュなしでデータを読み書きしたいだけの場合には、必須であるべきではありません。
デスクトップタイプのシステムであっても、通常のNVMeデバイスは数秒でページキャッシュ全体を埋め尽くす可能性があります。私がテストに使用した大規模システムでは、RAMはさらに多いですが、デバイスもさらに多くあります。以下のパッチの一部で見られる結果からもわかるように、1TBのRAMがあっても、数秒でRAMを埋め尽くすことができます。したがって、この問題は「大規模なハイパースケーラシステム」だけの問題ではなく、あらゆる場面で共通の問題です。
要約すると、読み書きの両方で約65%のパフォーマンス向上、完全に予測可能なIO時間を確認しています。CPU使用率の削減も大幅で、キャッシュされていないIOを使用した場合、リクレイムのためのkswapdアクティビティは一切ありません。
アプリケーションから使用するのは簡単です。preadv2(2)またはpreadv2(2)を使用して、読み込みまたは書き込みにRWF_DONTCACHEを設定するだけです。io_uringの場合も同様に、バッファ付き読み込み/書き込み操作のsqe->rw_flagsにRWF_DONTCACHEを設定するだけです。以上です。
[PATCH 01/12] mm/filemap: change filemap_create_folio() to take a struct kiocb
このパッチは filemap_create_folio() をリファクタリングし、必要な情報を kiocb 構造体から取得するように変更します。機能的な変更はなく、後続のパッチのための準備となります
diff --git a/mm/filemap.c b/mm/filemap.c
index f61cf51c2238..8b29323b15d7 100644
--- a/mm/filemap.c
+++ b/mm/filemap.c
@@ -2459,15 +2459,17 @@ static int filemap_update_page(struct kiocb *iocb,
return error;
}
-static int filemap_create_folio(struct file *file,
- struct address_space *mapping, loff_t pos,
- struct folio_batch *fbatch)
+static int filemap_create_folio(struct kiocb *iocb, struct folio_batch *fbatch)
{
+ struct address_space *mapping = iocb->ki_filp->f_mapping;
struct folio *folio;
int error;
unsigned int min_order = mapping_min_folio_order(mapping);
pgoff_t index;
+ if (iocb->ki_flags & (IOCB_NOWAIT | IOCB_WAITQ))
+ return -EAGAIN;
+
folio = filemap_alloc_folio(mapping_gfp_mask(mapping), min_order);
if (!folio)
return -ENOMEM;
@@ -2486,7 +2488,7 @@ static int filemap_create_folio(struct file *file,
* well to keep locking rules simple.
*/
filemap_invalidate_lock_shared(mapping);
- index = (pos >> (PAGE_SHIFT + min_order)) << min_order;
+ index = (iocb->ki_pos >> (PAGE_SHIFT + min_order)) << min_order;
error = filemap_add_folio(mapping, folio, index,
mapping_gfp_constraint(mapping, GFP_KERNEL));
if (error == -EEXIST)
@@ -2494,7 +2496,8 @@ static int filemap_create_folio(struct file *file,
if (error)
goto error;
- error = filemap_read_folio(file, mapping->a_ops->read_folio, folio);
+ error = filemap_read_folio(iocb->ki_filp, mapping->a_ops->read_folio,
+ folio);
if (error)
goto error;
@@ -2550,9 +2553,7 @@ static int filemap_get_pages(struct kiocb *iocb, size_t count,
filemap_get_read_batch(mapping, index, last_index - 1, fbatch);
}
if (!folio_batch_count(fbatch)) {
- if (iocb->ki_flags & (IOCB_NOWAIT | IOCB_WAITQ))
- return -EAGAIN;
- err = filemap_create_folio(filp, mapping, iocb->ki_pos, fbatch);
+ err = filemap_create_folio(iocb, fbatch);
if (err == AOP_TRUNCATED_PAGE)
goto retry;
return err;
--
2.45.2[PATCH 02/12] mm/filemap: use page_cache_sync_ra() to kick off read-ahead
このパッチは filemap_get_pages() 関数において page_cache_sync_readahead() の代わりにpage_cache_sync_ra() を直接使用するように変更します。
コミットメッセージにあるように filemap_get_pages() 内で ractl を変更する必要があるための準備となります。機能的な変更はなくリファクタリングが主な目的です。
diff --git a/mm/filemap.c b/mm/filemap.c
index 8b29323b15d7..220dc7c6e12f 100644
--- a/mm/filemap.c
+++ b/mm/filemap.c
@@ -2527,7 +2527,6 @@ static int filemap_get_pages(struct kiocb *iocb, size_t count,
{
struct file *filp = iocb->ki_filp;
struct address_space *mapping = filp->f_mapping;
- struct file_ra_state *ra = &filp->f_ra;
pgoff_t index = iocb->ki_pos >> PAGE_SHIFT;
pgoff_t last_index;
struct folio *folio;
@@ -2542,12 +2541,13 @@ static int filemap_get_pages(struct kiocb *iocb, size_t count,
filemap_get_read_batch(mapping, index, last_index - 1, fbatch);
if (!folio_batch_count(fbatch)) {
+ DEFINE_READAHEAD(ractl, filp, &filp->f_ra, mapping, index);
+
if (iocb->ki_flags & IOCB_NOIO)
return -EAGAIN;
if (iocb->ki_flags & IOCB_NOWAIT)
flags = memalloc_noio_save();
- page_cache_sync_readahead(mapping, ra, filp, index,
- last_index - index);
+ page_cache_sync_ra(&ractl, last_index - index);
if (iocb->ki_flags & IOCB_NOWAIT)
memalloc_noio_restore(flags);
filemap_get_read_batch(mapping, index, last_index - 1, fbatch);
--
2.45.2include/linux/pagemap.h#L1391-L1398
static inline
void page_cache_sync_readahead(struct address_space *mapping,
struct file_ra_state *ra, struct file *file, pgoff_t index,
unsigned long req_count)
{
DEFINE_READAHEAD(ractl, file, ra, mapping, index);
page_cache_sync_ra(&ractl, req_count);
}[PATCH 03/12] mm/readahead: add folio allocation helper
このパッチは、folio のアロケーション処理を抽象化するために ractl_alloc_folio() ヘルパー関数を追加します。現時点では filemap_alloc_folio() の単純なラッパー関数に過ぎませんが、コミットメッセージにあるように、将来的に ractl に基づいて folio の割り当て方法を変更するための準備となります。
folio は Linux 5.16で導入されたメモリ管理方法で、連続したページをまとめて管理できる新しいデータ構造です。別で解説記事を上げる予定なので、上がったら追記します。
このパッチ自体に機能的な変更はありません。
diff --git a/mm/readahead.c b/mm/readahead.c
index ea650b8b02fb..8a62ad4106ff 100644
--- a/mm/readahead.c
+++ b/mm/readahead.c
@@ -188,6 +188,12 @@ static void read_pages(struct readahead_control *rac)
BUG_ON(readahead_count(rac));
}
+static struct folio *ractl_alloc_folio(struct readahead_control *ractl,
+ gfp_t gfp_mask, unsigned int order)
+{
+ return filemap_alloc_folio(gfp_mask, order);
+}
+
/**
* page_cache_ra_unbounded - Start unchecked readahead.
* @ractl: Readahead control.
@@ -265,8 +271,8 @@ void page_cache_ra_unbounded(struct readahead_control *ractl,
continue;
}
- folio = filemap_alloc_folio(gfp_mask,
- mapping_min_folio_order(mapping));
+ folio = ractl_alloc_folio(ractl, gfp_mask,
+ mapping_min_folio_order(mapping));
if (!folio)
break;
@@ -436,7 +442,7 @@ static inline int ra_alloc_folio(struct readahead_control *ractl, pgoff_t index,
pgoff_t mark, unsigned int order, gfp_t gfp)
{
int err;
- struct folio *folio = filemap_alloc_folio(gfp, order);
+ struct folio *folio = ractl_alloc_folio(ractl, gfp, order);
if (!folio)
return -ENOMEM;
@@ -750,7 +756,7 @@ void readahead_expand(struct readahead_control *ractl,
if (folio && !xa_is_value(folio))
return; /* Folio apparently present */
- folio = filemap_alloc_folio(gfp_mask, min_order);
+ folio = ractl_alloc_folio(ractl, gfp_mask, min_order);
if (!folio)
return;
@@ -779,7 +785,7 @@ void readahead_expand(struct readahead_control *ractl,
if (folio && !xa_is_value(folio))
return; /* Folio apparently present */
- folio = filemap_alloc_folio(gfp_mask, min_order);
+ folio = ractl_alloc_folio(ractl, gfp_mask, min_order);
if (!folio)
return;
--
2.45.2[PATCH 04/12] mm: add PG_dropbehind folio flag
このパッチは、PG_dropbehind という新しい folio フラグをカーネルに追加します。
このフラグはI/O操作でページキャッシュに読み込まれたデータが、そのI/O操作の完了後に不要となり、ページキャッシュから積極的に削除しても良い(dropbehind)ことを示すために使用されます。
このパッチ自体に機能的な変更はありません。
diff --git a/include/linux/page-flags.h b/include/linux/page-flags.h
index cf46ac720802..16607f02abd0 100644
--- a/include/linux/page-flags.h
+++ b/include/linux/page-flags.h
@@ -110,6 +110,7 @@ enum pageflags {
PG_reclaim, /* To be reclaimed asap */
PG_swapbacked, /* Page is backed by RAM/swap */
PG_unevictable, /* Page is "unevictable" */
+ PG_dropbehind, /* drop pages on IO completion */
#ifdef CONFIG_MMU
PG_mlocked, /* Page is vma mlocked */
#endif
@@ -562,6 +563,10 @@ PAGEFLAG(Reclaim, reclaim, PF_NO_TAIL)
FOLIO_FLAG(readahead, FOLIO_HEAD_PAGE)
FOLIO_TEST_CLEAR_FLAG(readahead, FOLIO_HEAD_PAGE)
+FOLIO_FLAG(dropbehind, FOLIO_HEAD_PAGE)
+ FOLIO_TEST_CLEAR_FLAG(dropbehind, FOLIO_HEAD_PAGE)
+ __FOLIO_SET_FLAG(dropbehind, FOLIO_HEAD_PAGE)
+
#ifdef CONFIG_HIGHMEM
/*
* Must use a macro here due to header dependency issues. page_zone() is not
diff --git a/include/trace/events/mmflags.h b/include/trace/events/mmflags.h
index bb8a59c6caa2..3bc8656c8359 100644
--- a/include/trace/events/mmflags.h
+++ b/include/trace/events/mmflags.h
@@ -116,7 +116,8 @@
DEF_PAGEFLAG_NAME(head), \
DEF_PAGEFLAG_NAME(reclaim), \
DEF_PAGEFLAG_NAME(swapbacked), \
- DEF_PAGEFLAG_NAME(unevictable) \
+ DEF_PAGEFLAG_NAME(unevictable), \
+ DEF_PAGEFLAG_NAME(dropbehind) \
IF_HAVE_PG_MLOCK(mlocked) \
IF_HAVE_PG_HWPOISON(hwpoison) \
IF_HAVE_PG_IDLE(idle) \
--
2.45.2#define FOLIO_FLAG(name, page) \
FOLIO_TEST_FLAG(name, page) \
FOLIO_SET_FLAG(name, page) \
FOLIO_CLEAR_FLAG(name, page)
#define FOLIO_TEST_FLAG(name, page) \
static __always_inline bool folio_test_##name(const struct folio *folio) \
{ return test_bit(PG_##name, const_folio_flags(folio, page)); }
#define FOLIO_SET_FLAG(name, page) \
static __always_inline void folio_set_##name(struct folio *folio) \
{ set_bit(PG_##name, folio_flags(folio, page)); }
#define FOLIO_CLEAR_FLAG(name, page) \
static __always_inline void folio_clear_##name(struct folio *folio) \
{ clear_bit(PG_##name, folio_flags(folio, page)); }[PATCH 05/12] mm/readahead: add readahead_control->dropbehind member
前パッチで追加された PG_dropbehind フラグを readahead でも使用できるようにするための変更です。
readahead_control 構造体に dropbehind メンバを追加し、ractl_alloc_folio() 関数内でこのフラグが真の場合に、割り当てられた folio に PG_dropbehind フラグを設定するようにしました。
これにより、readahead で読み込まれたページを、必要に応じて dropbehind としてマークすることが可能になります。これは大量のデータを連続的に読み込むようなケースで役立ちます。
このパッチ自体に機能的な変更はありません。
diff --git a/include/linux/pagemap.h b/include/linux/pagemap.h
index bcf0865a38ae..5da4b6d42fae 100644
--- a/include/linux/pagemap.h
+++ b/include/linux/pagemap.h
@@ -1353,6 +1353,7 @@ struct readahead_control {
pgoff_t _index;
unsigned int _nr_pages;
unsigned int _batch_count;
+ bool dropbehind;
bool _workingset;
unsigned long _pflags;
};
diff --git a/mm/readahead.c b/mm/readahead.c
index 8a62ad4106ff..c0a6dc5d5686 100644
--- a/mm/readahead.c
+++ b/mm/readahead.c
@@ -191,7 +191,13 @@ static void read_pages(struct readahead_control *rac)
static struct folio *ractl_alloc_folio(struct readahead_control *ractl,
gfp_t gfp_mask, unsigned int order)
{
- return filemap_alloc_folio(gfp_mask, order);
+ struct folio *folio;
+
+ folio = filemap_alloc_folio(gfp_mask, order);
+ if (folio && ractl->dropbehind)
+ __folio_set_dropbehind(folio);
+
+ return folio;
}
/**
--
2.45.2[PATCH 06/12] mm/truncate: add folio_unmap_invalidate() helper
folio の unmap と無効化処理を共通化するためのヘルパー関数 folio_unmap_invalidate() を導入します。
invalidate_inode_pages2_range() 関数でのコード処理をヘルパー関数に切り出し、簡潔にしました。
また、gfp_t 引数を導入することで、folio_unmap_invalidate() 関数が GFP_KERNEL 以外のメモリ割り当てでも使用できるようになりました。
このパッチ自体に機能的な変更はありません。
diff --git a/mm/internal.h b/mm/internal.h
index cb8d8e8e3ffa..ed3c3690eb03 100644
--- a/mm/internal.h
+++ b/mm/internal.h
@@ -392,6 +392,8 @@ void unmap_page_range(struct mmu_gather *tlb,
struct vm_area_struct *vma,
unsigned long addr, unsigned long end,
struct zap_details *details);
+int folio_unmap_invalidate(struct address_space *mapping, struct folio *folio,
+ gfp_t gfp);
void page_cache_ra_order(struct readahead_control *, struct file_ra_state *,
unsigned int order);
diff --git a/mm/truncate.c b/mm/truncate.c
index 7c304d2f0052..e2e115adfbc5 100644
--- a/mm/truncate.c
+++ b/mm/truncate.c
@@ -525,6 +525,15 @@ unsigned long invalidate_mapping_pages(struct address_space *mapping,
}
EXPORT_SYMBOL(invalidate_mapping_pages);
+static int folio_launder(struct address_space *mapping, struct folio *folio)
+{
+ if (!folio_test_dirty(folio))
+ return 0;
+ if (folio->mapping != mapping || mapping->a_ops->launder_folio == NULL)
+ return 0;
+ return mapping->a_ops->launder_folio(folio);
+}
+
/*
* This is like mapping_evict_folio(), except it ignores the folio's
* refcount. We do this because invalidate_inode_pages2() needs stronger
@@ -532,14 +541,26 @@ EXPORT_SYMBOL(invalidate_mapping_pages);
* shrink_folio_list() has a temp ref on them, or because they're transiently
* sitting in the folio_add_lru() caches.
*/
-static int invalidate_complete_folio2(struct address_space *mapping,
- struct folio *folio)
+int folio_unmap_invalidate(struct address_space *mapping, struct folio *folio,
+ gfp_t gfp)
{
- if (folio->mapping != mapping)
- return 0;
+ int ret;
+
+ VM_BUG_ON_FOLIO(!folio_test_locked(folio), folio);
- if (!filemap_release_folio(folio, GFP_KERNEL))
+ if (folio_test_dirty(folio))
return 0;
+ if (folio_mapped(folio))
+ unmap_mapping_folio(folio);
+ BUG_ON(folio_mapped(folio));
+
+ ret = folio_launder(mapping, folio);
+ if (ret)
+ return ret;
+ if (folio->mapping != mapping)
+ return -EBUSY;
+ if (!filemap_release_folio(folio, gfp))
+ return -EBUSY;
spin_lock(&mapping->host->i_lock);
xa_lock_irq(&mapping->i_pages);
@@ -558,16 +579,7 @@ static int invalidate_complete_folio2(struct address_space *mapping,
failed:
xa_unlock_irq(&mapping->i_pages);
spin_unlock(&mapping->host->i_lock);
- return 0;
-}
-
-static int folio_launder(struct address_space *mapping, struct folio *folio)
-{
- if (!folio_test_dirty(folio))
- return 0;
- if (folio->mapping != mapping || mapping->a_ops->launder_folio == NULL)
- return 0;
- return mapping->a_ops->launder_folio(folio);
+ return -EBUSY;
}
/**
@@ -631,16 +643,7 @@ int invalidate_inode_pages2_range(struct address_space *mapping,
}
VM_BUG_ON_FOLIO(!folio_contains(folio, indices[i]), folio);
folio_wait_writeback(folio);
-
- if (folio_mapped(folio))
- unmap_mapping_folio(folio);
- BUG_ON(folio_mapped(folio));
-
- ret2 = folio_launder(mapping, folio);
- if (ret2 == 0) {
- if (!invalidate_complete_folio2(mapping, folio))
- ret2 = -EBUSY;
- }
+ ret2 = folio_unmap_invalidate(mapping, folio, GFP_KERNEL);
if (ret2 < 0)
ret = ret2;
folio_unlock(folio);
--
2.45.2[PATCH 07/12] fs: add RWF_DONTCACHE iocb and FOP_DONTCACHE file_operations flag
RWF_DONTCACHE 機能のユーザー空間インターフェースとファイルシステム側のサポート機構を導入する重要なパッチです。
・RWF_DONTCACHE:
ユーザー空間アプリケーションが preadv2 や pwritev2 システムコール、io_uring などを介してUncached Buffered I/Oをカーネルに要求するためのフラグです。
・FOP_DONTCACHE:
ファイルシステムが RWF_DONTCACHE をサポートすることを表明するためのフラグです。ファイルシステムがこのフラグを設定することで、カーネルは RWF_DONTCACHE リクエストを受け付けるようになります。
・エラーチェック:
カーネルは RWF_DONTCACHE リクエストを受け付ける前に、ファイルシステムが FOP_DONTCACHE フラグを設定しているかどうか、および DAX マッピングが有効になっていないかどうかをチェックします。これらの条件が満たされない場合、-EOPNOTSUPP エラーを返します。
diff --git a/include/linux/fs.h b/include/linux/fs.h
index 7e29433c5ecc..6a838b5479a6 100644
--- a/include/linux/fs.h
+++ b/include/linux/fs.h
@@ -322,6 +322,7 @@ struct readahead_control;
#define IOCB_NOWAIT (__force int) RWF_NOWAIT
#define IOCB_APPEND (__force int) RWF_APPEND
#define IOCB_ATOMIC (__force int) RWF_ATOMIC
+#define IOCB_DONTCACHE (__force int) RWF_DONTCACHE
/* non-RWF related bits - start at 16 */
#define IOCB_EVENTFD (1 << 16)
@@ -356,7 +357,8 @@ struct readahead_control;
{ IOCB_SYNC, "SYNC" }, \
{ IOCB_NOWAIT, "NOWAIT" }, \
{ IOCB_APPEND, "APPEND" }, \
- { IOCB_ATOMIC, "ATOMIC"}, \
+ { IOCB_ATOMIC, "ATOMIC" }, \
+ { IOCB_DONTCACHE, "DONTCACHE" }, \
{ IOCB_EVENTFD, "EVENTFD"}, \
{ IOCB_DIRECT, "DIRECT" }, \
{ IOCB_WRITE, "WRITE" }, \
@@ -2127,6 +2129,8 @@ struct file_operations {
#define FOP_UNSIGNED_OFFSET ((__force fop_flags_t)(1 << 5))
/* Supports asynchronous lock callbacks */
#define FOP_ASYNC_LOCK ((__force fop_flags_t)(1 << 6))
+/* File system supports uncached read/write buffered IO */
+#define FOP_DONTCACHE ((__force fop_flags_t)(1 << 7))
/* Wrap a directory iterator that needs exclusive inode access */
int wrap_directory_iterator(struct file *, struct dir_context *,
@@ -3614,6 +3618,14 @@ static inline int kiocb_set_rw_flags(struct kiocb *ki, rwf_t flags,
if (!(ki->ki_filp->f_mode & FMODE_CAN_ATOMIC_WRITE))
return -EOPNOTSUPP;
}
+ if (flags & RWF_DONTCACHE) {
+ /* file system must support it */
+ if (!(ki->ki_filp->f_op->fop_flags & FOP_DONTCACHE))
+ return -EOPNOTSUPP;
+ /* DAX mappings not supported */
+ if (IS_DAX(ki->ki_filp->f_mapping->host))
+ return -EOPNOTSUPP;
+ }
kiocb_flags |= (__force int) (flags & RWF_SUPPORTED);
if (flags & RWF_SYNC)
kiocb_flags |= IOCB_DSYNC;
diff --git a/include/uapi/linux/fs.h b/include/uapi/linux/fs.h
index 753971770733..56a4f93a08f4 100644
--- a/include/uapi/linux/fs.h
+++ b/include/uapi/linux/fs.h
@@ -332,9 +332,13 @@ typedef int __bitwise __kernel_rwf_t;
/* Atomic Write */
#define RWF_ATOMIC ((__force __kernel_rwf_t)0x00000040)
+/* buffered IO that drops the cache after reading or writing data */
+#define RWF_DONTCACHE ((__force __kernel_rwf_t)0x00000080)
+
/* mask of flags supported by the kernel */
#define RWF_SUPPORTED (RWF_HIPRI | RWF_DSYNC | RWF_SYNC | RWF_NOWAIT |\
- RWF_APPEND | RWF_NOAPPEND | RWF_ATOMIC)
+ RWF_APPEND | RWF_NOAPPEND | RWF_ATOMIC |\
+ RWF_DONTCACHE)
#define PROCFS_IOCTL_MAGIC 'f'
--
2.45.2[PATCH 08/12] mm/filemap: add read support for RWF_DONTCACHE
RWF_DONTCACHE によるキャッシュバイパス機能の読み込み部分を実装します。
・dropbehindフラグ設定:
filemap_create_folio(), filemap_readahead(), filemap_get_pages() 関数内で、IOCB_DONTCACHE フラグが設定されている場合に、folio または readahead control 構造体 (ractl) に PG_dropbehind フラグを設定することで、後続の処理で dropbehind 対象の folio を識別できるようにします。
・dropbehind処理:
filemap_end_dropbehind_read() 関数で、読み取り操作完了後の folio の dropbehind 処理を行います。PG_dropbehind フラグが設定されている folio を unmap および無効化(folio_unmap_invalidate 関数)することで、ページキャッシュから削除し、RWF_DONTCACHE の意図である「キャッシュに残さない」動作を実現します。
・性能改善: コミットメッセージで示されているように RWF_DONTCACHE を使用することで、通常のBuffered I/Oに比べて大幅な性能向上とCPU使用率の削減が期待できます。これは、ページキャッシュのリクレイム処理によるオーバーヘッドを回避できるためです。
・Direct I/Oとの比較:
Direct I/O の制約 (アラインメント、同期IOなど) がなく、Buffered I/Oの利点 (ページキャッシュによる同期、readahead) を享受しつつ、キャッシュ汚染を抑制できる、より柔軟で高性能なI/O方式を提供することができます。
・swap.c の修正:
folio_mark_accessed() で dropbehind folio を処理対象外とすることでLRU管理から除外し、処理効率を高める意図と考えられます。
diff --git a/mm/filemap.c b/mm/filemap.c
index 220dc7c6e12f..dd563208d09d 100644
--- a/mm/filemap.c
+++ b/mm/filemap.c
@@ -2473,6 +2473,8 @@ static int filemap_create_folio(struct kiocb *iocb, struct folio_batch *fbatch)
folio = filemap_alloc_folio(mapping_gfp_mask(mapping), min_order);
if (!folio)
return -ENOMEM;
+ if (iocb->ki_flags & IOCB_DONTCACHE)
+ __folio_set_dropbehind(folio);
/*
* Protect against truncate / hole punch. Grabbing invalidate_lock
@@ -2518,6 +2520,8 @@ static int filemap_readahead(struct kiocb *iocb, struct file *file,
if (iocb->ki_flags & IOCB_NOIO)
return -EAGAIN;
+ if (iocb->ki_flags & IOCB_DONTCACHE)
+ ractl.dropbehind = 1;
page_cache_async_ra(&ractl, folio, last_index - folio->index);
return 0;
}
@@ -2547,6 +2551,8 @@ static int filemap_get_pages(struct kiocb *iocb, size_t count,
return -EAGAIN;
if (iocb->ki_flags & IOCB_NOWAIT)
flags = memalloc_noio_save();
+ if (iocb->ki_flags & IOCB_DONTCACHE)
+ ractl.dropbehind = 1;
page_cache_sync_ra(&ractl, last_index - index);
if (iocb->ki_flags & IOCB_NOWAIT)
memalloc_noio_restore(flags);
@@ -2594,6 +2600,20 @@ static inline bool pos_same_folio(loff_t pos1, loff_t pos2, struct folio *folio)
return (pos1 >> shift == pos2 >> shift);
}
+static void filemap_end_dropbehind_read(struct address_space *mapping,
+ struct folio *folio)
+{
+ if (!folio_test_dropbehind(folio))
+ return;
+ if (folio_test_writeback(folio) || folio_test_dirty(folio))
+ return;
+ if (folio_trylock(folio)) {
+ if (folio_test_clear_dropbehind(folio))
+ folio_unmap_invalidate(mapping, folio, 0);
+ folio_unlock(folio);
+ }
+}
+
/**
* filemap_read - Read data from the page cache.
* @iocb: The iocb to read.
@@ -2707,8 +2727,12 @@ ssize_t filemap_read(struct kiocb *iocb, struct iov_iter *iter,
}
}
put_folios:
- for (i = 0; i < folio_batch_count(&fbatch); i++)
- folio_put(fbatch.folios[i]);
+ for (i = 0; i < folio_batch_count(&fbatch); i++) {
+ struct folio *folio = fbatch.folios[i];
+
+ filemap_end_dropbehind_read(mapping, folio);
+ folio_put(folio);
+ }
folio_batch_init(&fbatch);
} while (iov_iter_count(iter) && iocb->ki_pos < isize && !error);
diff --git a/mm/swap.c b/mm/swap.c
index 10decd9dffa1..ba02bd5ba145 100644
--- a/mm/swap.c
+++ b/mm/swap.c
@@ -427,6 +427,8 @@ static void folio_inc_refs(struct folio *folio)
*/
void folio_mark_accessed(struct folio *folio)
{
+ if (folio_test_dropbehind(folio))
+ return;
if (lru_gen_enabled()) {
folio_inc_refs(folio);
return;
--
2.45.2[PATCH 09/12] mm/filemap: drop streaming/uncached pages when writeback completes
RWF_DONTCACHE によるキャッシュバイパス機能の書き込み部分を実装します。
・folio_end_dropbehind_write() 関数:
ライトバック完了時に呼び出され、PG_dropbehind フラグが設定された folio を unmap および無効化することで、ページキャッシュから削除します。これにより、書き込み操作でも RWF_DONTCACHE の意図通りキャッシュに残さない動作が実現されます。
・folio_end_writeback() 関数の修正:
folio が dirty でない場合 (書き込み完了時) に folio_end_dropbehind_write() を呼び出すように変更されました。これにより、RWF_DONTCACHE 書き込みにおいて、データがディスクに書き込まれた後、ページキャッシュからフォリオが削除されるようになります。
RWF_DONTCACHE 書き込みは非同期で行われ、ライトバック完了後に dropbehind 処理が行われます。これにより、書き込み処理自体は高速に完了し、キャッシュ削除はバックグラウンドで行われるため、性能とキャッシュ効率の両立が可能となります。
特にストリーミングI/Oのような一時的なデータ処理を想定しており、キャッシュに残す必要がない、またはキャッシュに残したくない場合に有効な機能です。
diff --git a/mm/filemap.c b/mm/filemap.c
index dd563208d09d..aa0b3af6533d 100644
--- a/mm/filemap.c
+++ b/mm/filemap.c
@@ -1599,6 +1599,27 @@ int folio_wait_private_2_killable(struct folio *folio)
}
EXPORT_SYMBOL(folio_wait_private_2_killable);
+/*
+ * If folio was marked as dropbehind, then pages should be dropped when writeback
+ * completes. Do that now. If we fail, it's likely because of a big folio -
+ * just reset dropbehind for that case and latter completions should invalidate.
+ */
+static void folio_end_dropbehind_write(struct folio *folio)
+{
+ /*
+ * Hitting !in_task() should not happen off RWF_DONTCACHE writeback,
+ * but can happen if normal writeback just happens to find dirty folios
+ * that were created as part of uncached writeback, and that writeback
+ * would otherwise not need non-IRQ handling. Just skip the
+ * invalidation in that case.
+ */
+ if (in_task() && folio_trylock(folio)) {
+ if (folio->mapping)
+ folio_unmap_invalidate(folio->mapping, folio, 0);
+ folio_unlock(folio);
+ }
+}
+
/**
* folio_end_writeback - End writeback against a folio.
* @folio: The folio.
@@ -1609,6 +1630,8 @@ EXPORT_SYMBOL(folio_wait_private_2_killable);
*/
void folio_end_writeback(struct folio *folio)
{
+ bool folio_dropbehind = false;
+
VM_BUG_ON_FOLIO(!folio_test_writeback(folio), folio);
/*
@@ -1630,9 +1653,14 @@ void folio_end_writeback(struct folio *folio)
* reused before the folio_wake_bit().
*/
folio_get(folio);
+ if (!folio_test_dirty(folio))
+ folio_dropbehind = folio_test_clear_dropbehind(folio);
if (__folio_end_writeback(folio))
folio_wake_bit(folio, PG_writeback);
acct_reclaim_writeback(folio);
+
+ if (folio_dropbehind)
+ folio_end_dropbehind_write(folio);
folio_put(folio);
}
EXPORT_SYMBOL(folio_end_writeback);
--
2.45.2
[PATCH 10/12] mm/filemap: add filemap_fdatawrite_range_kick() helper
RWF_DONTCACHE の書き込み処理を実装する上で必要な、新しいライトバック開始ヘルパー関数 filemap_fdatawrite_range_kick() を追加します。
指定されたアドレス空間と範囲に対して、整合性を保証しない通常のデータライトバック(WB_SYNC_NONE)を開始します。
diff --git a/mm/filemap.c b/mm/filemap.c
index aa0b3af6533d..9842258ba343 100644
--- a/mm/filemap.c
+++ b/mm/filemap.c
@@ -449,6 +449,24 @@ int filemap_fdatawrite_range(struct address_space *mapping, loff_t start,
}
EXPORT_SYMBOL(filemap_fdatawrite_range);
+/**
+ * filemap_fdatawrite_range_kick - start writeback on a range
+ * @mapping: target address_space
+ * @start: index to start writeback on
+ * @end: last (non-inclusive) index for writeback
+ *
+ * This is a non-integrity writeback helper, to start writing back folios
+ * for the indicated range.
+ *
+ * Return: %0 on success, negative error code otherwise.
+ */
+int filemap_fdatawrite_range_kick(struct address_space *mapping, loff_t start,
+ loff_t end)
+{
+ return __filemap_fdatawrite_range(mapping, start, end, WB_SYNC_NONE);
+}
+EXPORT_SYMBOL_GPL(filemap_fdatawrite_range_kick);
+
/**
* filemap_flush - mostly a non-blocking flush
* @mapping: target address_space
--
2.45.2既存の filemap_fdatawrite_range() 関数は整合性を保証するライトバック(WB_SYNC_ALL)を行うため、RWF_DONTCACHE のようなキャッシュバイパスI/Oには適していません。
そのため、新規で filemap_fdatawrite_range_kick() を追加したという流れです。
int filemap_fdatawrite_range(struct address_space *mapping, loff_t start,
loff_t end)
{
return __filemap_fdatawrite_range(mapping, start, end, WB_SYNC_ALL);
}
EXPORT_SYMBOL(filemap_fdatawrite_range);
int filemap_fdatawrite_range_kick(struct address_space *mapping, loff_t start,
loff_t end)
{
return __filemap_fdatawrite_range(mapping, start, end, WB_SYNC_NONE);
}
EXPORT_SYMBOL_GPL(filemap_fdatawrite_range_kick);[PATCH 11/12] mm: call filemap_fdatawrite_range_kick() after IOCB_DONTCACHE issue
RWF_DONTCACHE 書き込みのライトバック処理をトリガーするロジックを generic_write_sync() 関数に追加します。
・generic_write_sync() 関数:
Buffered Write 処理の最後に呼び出される汎用的な同期関数です。
パッチ10 で追加された filemap_fdatawrite_range_kick() 関数を generic_write_sync() から呼び出すことで、RWF_DONTCACHE フラグが設定された書き込み操作に対して、書き込みデータがページキャッシュに格納された後、ライトバック処理が開始されるようになります。
generic_write_sync() は汎用的な関数でありファイルシステムに依存しないため、個々のファイルシステムを修正することなく、RWF_DONTCACHE の書き込みサポートをファイルシステム全体に適用することが可能になります。
また、ライトバック処理は非同期で行われ、完了後にパッチ9 で実装された folio_end_dropbehind_write() 関数によって dropbehind 処理が行われます。
diff --git a/include/linux/fs.h b/include/linux/fs.h
index 653b5efa3d3f..58a618853574 100644
--- a/include/linux/fs.h
+++ b/include/linux/fs.h
@@ -2912,6 +2912,11 @@ static inline ssize_t generic_write_sync(struct kiocb *iocb, ssize_t count)
(iocb->ki_flags & IOCB_SYNC) ? 0 : 1);
if (ret)
return ret;
+ } else if (iocb->ki_flags & IOCB_DONTCACHE) {
+ struct address_space *mapping = iocb->ki_filp->f_mapping;
+
+ filemap_fdatawrite_range_kick(mapping, iocb->ki_pos,
+ iocb->ki_pos + count);
}
return count;
--
2.45.2[PATCH 12/12] mm: add FGP_DONTCACHE folio creation flag
folio 取得処理 (__filemap_get_folio) における RWF_DONTCACHE サポートを完成させるための調整を行います。
・FGP_DONTCACHE フラグ:
folio 取得時に FGP_DONTCACHE フラグを指定することで、呼び出し元はキャッシュバイパスI/Oのための folio 取得であることを __filemap_get_folio() 関数に通知できます。
・新規 folio 作成時の dropbehind 設定:
FGP_DONTCACHE フラグが指定されて folio が新規作成された場合、PG_dropbehind フラグが設定されます。これにより、作成直後から dropbehind 対象の folio として扱われるようになります。
FGP_DONTCACHE フラグなしで folio 取得を行った際に、既存の folio が PG_dropbehind フラグを持っている場合、そのフラグをクリアします。
これは、キャッシュバイパスI/Oと通常のキャッシュI/Oが同じ folio を共有する場合に、通常のキャッシュI/Oが意図せず dropbehind されてしまうことを防ぐためです。
diff --git a/include/linux/pagemap.h b/include/linux/pagemap.h
index 5da4b6d42fae..64c6dada837e 100644
--- a/include/linux/pagemap.h
+++ b/include/linux/pagemap.h
@@ -710,6 +710,7 @@ pgoff_t page_cache_prev_miss(struct address_space *mapping,
* * %FGP_NOFS - __GFP_FS will get cleared in gfp.
* * %FGP_NOWAIT - Don't block on the folio lock.
* * %FGP_STABLE - Wait for the folio to be stable (finished writeback)
+ * * %FGP_DONTCACHE - Uncached buffered IO
* * %FGP_WRITEBEGIN - The flags to use in a filesystem write_begin()
* implementation.
*/
@@ -723,6 +724,7 @@ typedef unsigned int __bitwise fgf_t;
#define FGP_NOWAIT ((__force fgf_t)0x00000020)
#define FGP_FOR_MMAP ((__force fgf_t)0x00000040)
#define FGP_STABLE ((__force fgf_t)0x00000080)
+#define FGP_DONTCACHE ((__force fgf_t)0x00000100)
#define FGF_GET_ORDER(fgf) (((__force unsigned)fgf) >> 26) /* top 6 bits */
#define FGP_WRITEBEGIN (FGP_LOCK | FGP_WRITE | FGP_CREAT | FGP_STABLE)
diff --git a/mm/filemap.c b/mm/filemap.c
index 9842258ba343..68bdfff4117e 100644
--- a/mm/filemap.c
+++ b/mm/filemap.c
@@ -2001,6 +2001,8 @@ struct folio *__filemap_get_folio(struct address_space *mapping, pgoff_t index,
/* Init accessed so avoid atomic mark_page_accessed later */
if (fgp_flags & FGP_ACCESSED)
__folio_set_referenced(folio);
+ if (fgp_flags & FGP_DONTCACHE)
+ __folio_set_dropbehind(folio);
err = filemap_add_folio(mapping, folio, index, gfp);
if (!err)
@@ -2023,6 +2025,9 @@ struct folio *__filemap_get_folio(struct address_space *mapping, pgoff_t index,
if (!folio)
return ERR_PTR(-ENOENT);
+ /* not an uncached lookup, clear uncached if set */
+ if (folio_test_dropbehind(folio) && !(fgp_flags & FGP_DONTCACHE))
+ folio_clear_dropbehind(folio);
return folio;
}
EXPORT_SYMBOL(__filemap_get_folio);
--
2.45.2まとめ
Uncached Buffered I/Oは Linux 6.14で導入される新しいI/O方式であり、従来のBuffered I/OとDirect I/Oの利点を組み合わせたものです。ページキャッシュのオーバーヘッドを回避することで、高性能、予測可能なI/O時間、低いCPU使用率を実現可能です。
特に高速なストレージに対して一過性のI/Oをよく発行するワークロードの場合、導入を検討することで性能が改善されるかもしれません。
今後の展望
Uncached Buffered I/Oは開発途上の技術であり、今後のLinuxカーネルのバージョンアップで更なる改良が加えられる可能性があります。
例えば、ファイルシステムやストレージデバイスとの連携強化、パフォーマンスチューニングなどが考えられます。また Uncached Buffered I/Oを効果的に活用するためのアプリケーション側のAPIやライブラリの開発も期待されます。
Uncached Buffered I/Oはデータベースアプリケーションや高性能コンピューティングなどの分野で特に有用であると思われます。
データベースでは大量のデータを高速に読み書きする必要があるため、Uncached Buffered I/Oの性能向上は大きなメリットとなりますし、高性能コンピューティングでは予測可能なI/O時間が重要となるため Uncached Buffered I/Oの安定した性能はシミュレーションやモデリングなどの処理に役立つはずです。