今回はLinux 6.12で高速化された VirtioVsock について、どのような改善が行われたのかLinuxのソースコードベース解説します。
目次
3行まとめ
- 従来の VirtioVsock は一度中間キューに追加し、workerが virtqueue に転送していた
- Linux 6.12 では中間キューを経由せず、直接 virtqueue へ送信できる経路が新設された
- これによりレイテンシが下がり、最大70%のスループット向上が実現した
VirtioVsockとは
VirtioVsock は Linux 4.8 で実装された、ホストOSとゲストVM間でソケットベースの通信を可能にする、vhostベースの仮想化技術です。
ゲストVMとホストOS上で動作するアプリケーションが、標準のソケットインターフェース (socket, connect, bind, listen, accept) を使用して相互に通信する方法を提供します。
従来の仮想マシン環境では、ホストOSとゲストVM間の通信に、仮想NICを用いたTCP/IP通信や、シリアルポートを用いた virtio-serial が利用されていました。
しかし、TCP/IP通信は設定が煩雑で、virtio-serial はソケットAPIをサポートしておらず、ポート数が512以下に限られているため、複数プロセス間の通信に課題がありました。
VirtioVsock はこれらの課題を解決し、よりシンプルで効率的な通信を実現しています。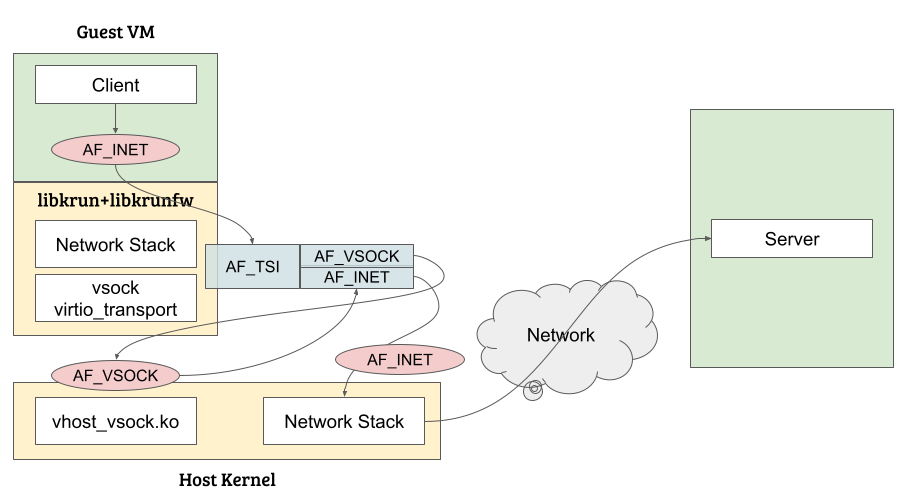
参照: “libkrunでのネットワーク通信”, 赤帽エンジニアブログ
VirtioVsockは以下の特徴を持ちます。
- ゼロコンフィギュレーション
- ゲストVM側でIPアドレスなどの設定が不要
- POSIX Sockets API
- 既存のネットワークアプリケーションを容易に移植可能
- 軽量
- TCP/IPスタックやネットワークインターフェースが不要
- セキュリティ
- TCP/IP通信に比べて攻撃対象領域を削減
- 多様なソケットタイプをサポート
- TCPのようなコネクション指向のストリームソケット(SOCK_STREAM)
UDPのようなコネクションレスのデータグラムソケット(SOCK_DGRAM)
- TCPのようなコネクション指向のストリームソケット(SOCK_STREAM)
VirtioVsockの仕組み
VirtioVsock は AF_VSOCK というアドレスファミリと (CID, ポート) の組み合わせによるアドレス指定を用います。CID (Context ID) は、ホストOSと各VMに割り当てられる識別子で、ホストOSのCIDは標準的に 2 が使用されます。
データ転送には virtio 標準の virtqueue と呼ばれるリングバッファが使用されます。
ゲストVMの virtio-vsock ドライバは、送信データを virtqueue に書き込み、VMM (Virtual Machine Monitor) に通知します。VMM は vhost-vsock カーネルモジュールを介してデータをホストOSのソケット層に転送します。
VirtioVsock は、RX、TX、イベントの3つの virtqueue を使用します。
RX virtqueue はゲストVMへのデータ受信、TX virtqueue はゲストVMからのデータ送信、イベント virtqueue は制御情報の送受信に使用されます。
VirtioVsock はホストOSとゲストVM間の通信に特化しており、軽量で設定が容易な点がメリットです。一方 TCP/IP のように広範囲なネットワーク通信には対応していません。Unix Domain Socket と比較すると VM 間の境界を越えて通信できる点が優れています。
Linux 6.12 で導入された高速化
ここからが本編です。VirtioVsock は Linux 6.12 で高速化の改善が行われました。
ここでは Linux 6.11 までの挙動と 6.12 の挙動を解説し、どのような改善がされたのか解説します。
Linux 6.11 まで
virtio_transport_send_pkt()
Linux 6.11までの VirtioVsock ドライバでは、送信パケットをいったん中間キューに蓄積し、カーネルのワークキュー経由で専用のワーカースレッドがそれらを virtio の送信リング(virtqueue)に投入する方式を取っていました。
// net/vmw_vsock/virtio_transport.c
static int
virtio_transport_send_pkt(struct sk_buff *skb)
{
struct virtio_vsock_hdr *hdr;
struct virtio_vsock *vsock;
int len = skb->len;
hdr = virtio_vsock_hdr(skb);
...
if (virtio_vsock_skb_reply(skb))
atomic_inc(&vsock->queued_replies);
virtio_vsock_skb_queue_tail(&vsock->send_pkt_queue, skb);
queue_work(virtio_vsock_workqueue, &vsock->send_pkt_work);
out_rcu:
rcu_read_unlock();
return len;
}具体的には、送信処理を行う関数 virtio_transport_send_pkt() が呼ばれると
14: まずパケット skb を中間キュー vsock->send_pkt_queue に追加
15: queue_work() を利用して virtio_vsock_workqueue 上に送信ワーク vsock->send_pkt_work をスケジューリング
ちなみに15行目の vsock->send_pkt_work は 初期化時に virtio_transport_send_pkt_work() で定義されています。
// net/vmw_vsock/virtio_transport.c
static int virtio_vsock_probe(struct virtio_device *vdev)
{
...
INIT_WORK(&vsock->send_pkt_work, virtio_transport_send_pkt_work)
...
}また、14行目の virtio_vsock_skb_queue_tail() についてはキューの末尾に要素を追加する関数です。
// include/linux/virtio_vsock.h
static inline void
virtio_vsock_skb_queue_tail(struct sk_buff_head *list, struct sk_buff *skb)
{
spin_lock_bh(&list->lock);
__skb_queue_tail(list, skb);
spin_unlock_bh(&list->lock);
}
// include/linux/skbuff.h
static inline void __skb_queue_tail(struct sk_buff_head *list,
struct sk_buff *newsk)
{
__skb_queue_before(list, (struct sk_buff *)list, newsk);
}
static inline void __skb_queue_before(struct sk_buff_head *list,
struct sk_buff *next,
struct sk_buff *newsk)
{
__skb_insert(newsk, ((struct sk_buff_list *)next)->prev, next, list);
}
static inline void __skb_insert(struct sk_buff *newsk,
struct sk_buff *prev, struct sk_buff *next,
struct sk_buff_head *list)
{
/* See skb_queue_empty_lockless() and skb_peek_tail()
* for the opposite READ_ONCE()
*/
WRITE_ONCE(newsk->next, next);
WRITE_ONCE(newsk->prev, prev);
WRITE_ONCE(((struct sk_buff_list *)next)->prev, newsk);
WRITE_ONCE(((struct sk_buff_list *)prev)->next, newsk);
WRITE_ONCE(list->qlen, list->qlen + 1);
}virtio_transport_send_pkt_work()
virtio_transport_send_pkt_work() はワーカーとして後続で実行され、中間キューからパケットを取り出してvirtioの送信リング(virtqueue)に投入します。
static void
virtio_transport_send_pkt_work(struct work_struct *work)
{
struct virtio_vsock *vsock =
container_of(work, struct virtio_vsock, send_pkt_work);
struct virtqueue *vq;
bool added = false;
bool restart_rx = false;
mutex_lock(&vsock->tx_lock);
if (!vsock->tx_run)
goto out;
vq = vsock->vqs[VSOCK_VQ_TX];
for (;;) {
int ret, in_sg = 0, out_sg = 0;
struct scatterlist **sgs;
struct sk_buff *skb;
bool reply;
skb = virtio_vsock_skb_dequeue(&vsock->send_pkt_queue);
if (!skb)
break;
reply = virtio_vsock_skb_reply(skb);
sgs = vsock->out_sgs;
sg_init_one(sgs[out_sg], virtio_vsock_hdr(skb),
sizeof(*virtio_vsock_hdr(skb)));
out_sg++;
if (!skb_is_nonlinear(skb)) {
if (skb->len > 0) {
sg_init_one(sgs[out_sg], skb->data, skb->len);
out_sg++;
}
} else {
struct skb_shared_info *si;
int i;
/* If skb is nonlinear, then its buffer must contain
* only header and nothing more. Data is stored in
* the fragged part.
*/
WARN_ON_ONCE(skb_headroom(skb) != sizeof(*virtio_vsock_hdr(skb)));
si = skb_shinfo(skb);
for (i = 0; i < si->nr_frags; i++) {
skb_frag_t *skb_frag = &si->frags[i];
void *va;
/* We will use 'page_to_virt()' for the userspace page
* here, because virtio or dma-mapping layers will call
* 'virt_to_phys()' later to fill the buffer descriptor.
* We don't touch memory at "virtual" address of this page.
*/
va = page_to_virt(skb_frag_page(skb_frag));
sg_init_one(sgs[out_sg],
va + skb_frag_off(skb_frag),
skb_frag_size(skb_frag));
out_sg++;
}
}
ret = virtqueue_add_sgs(vq, sgs, out_sg, in_sg, skb, GFP_KERNEL);
/* Usually this means that there is no more space available in
* the vq
*/
if (ret < 0) {
virtio_vsock_skb_queue_head(&vsock->send_pkt_queue, skb);
break;
}
virtio_transport_deliver_tap_pkt(skb);
if (reply) {
struct virtqueue *rx_vq = vsock->vqs[VSOCK_VQ_RX];
int val;
val = atomic_dec_return(&vsock->queued_replies);
/* Do we now have resources to resume rx processing? */
if (val + 1 == virtqueue_get_vring_size(rx_vq))
restart_rx = true;
}
added = true;
}
if (added)
virtqueue_kick(vq);
out:
mutex_unlock(&vsock->tx_lock);
if (restart_rx)
queue_work(virtio_vsock_workqueue, &vsock->rx_work);
}15: virtioの送信リング vsock->vqs[VSOCK_VQ_TX] を vq と定義します(virtqueue)
23: 中間キュー vsock->send_pkt_queue からパケット skb を取り出します
28: vsock->out_sgs を sgs と定義します。sgs はデータの位置を示す構造体 sg (struct scatterlist) の配列です(後で説明します)
29: sgs[0] に skb のヘッダの位置を書き込みます
35: skb がライナーな時、sgs[1] に skb のデータの位置を書き込みます
60: skb がライナーで無い時、skb_shinfo() で取得できた各フラグメントの位置を sgs[] に書き込みます
67: virtqueue_add_sgs() を用いてパケットのヘッダとデータ sgs を vq に追加します
72: 失敗したら中間キューにパケットを戻します
93: vq にデータを追加した場合 virtqueue_kick() を使って起こします
sg (struct scatterlist)について
ページのリンク、オフセット、サイズ、アドレスを持つ構造体です。
これの配列を持つことで、データがどこに置かれているかを記録します。
// net/vmw_vsock/virtio_transport.c
struct virtio_vsock {
...
/* These fields are used only in tx path in function
* 'virtio_transport_send_pkt_work()', so to save
* stack space in it, place both of them here. Each
* pointer from 'out_sgs' points to the corresponding
* element in 'out_bufs' - this is initialized in
* 'virtio_vsock_probe()'. Both fields are protected
* by 'tx_lock'. +1 is needed for packet header.
*/
struct scatterlist *out_sgs[MAX_SKB_FRAGS + 1];
struct scatterlist out_bufs[MAX_SKB_FRAGS + 1];
};
// include/linux/skbuff.h
#ifndef CONFIG_MAX_SKB_FRAGS
# define CONFIG_MAX_SKB_FRAGS 17
#endif
#define MAX_SKB_FRAGS CONFIG_MAX_SKB_FRAGS
// include/linux/scatterlist.h
struct scatterlist {
unsigned long page_link;
unsigned int offset;
unsigned int length;
dma_addr_t dma_address;
#ifdef CONFIG_NEED_SG_DMA_LENGTH
unsigned int dma_length;
#endif
#ifdef CONFIG_NEED_SG_DMA_FLAGS
unsigned int dma_flags;
#endif
};まとめ
このように、送信元のスレッドはパケットを中間キューに入れるだけで実際の送信処理は非同期に行われます。これにより送信処理中の待ち時間を発生させずに順序保証を実現していました。
例えるならば、バッチ処理に近い形で実行していたという感じでしょうか。
Linux 6.12 以降
Linux 6.12 では、上記の VirtioVsock 送信処理に対し高速化のための改良が加えられました。
変更後は virtio の送信リング (virtqueue) に空きがあり、かつ中間キューが空の場合には、パケットを中間キューで経由にせず直接 virtqueue に投入するようになっています。
パッチはこちら:
[PATCH net-next v4 0/2] vsock: avoid queuing on intermediate queue if possible
[PATCH net-next v4 1/2] vsock/virtio: refactor virtio_transport_send_pkt_work
ワーカーとして起動していた virtio_transport_send_pkt_work() の処理本体を virtio_transport_send_skb() という別関数に切り出しました。これは準備パッチであり挙動に変更はありません。
diff --git a/net/vmw_vsock/virtio_transport.c b/net/vmw_vsock/virtio_transport.c
index 64a07acfef12..f641e906f351 100644
--- a/net/vmw_vsock/virtio_transport.c
+++ b/net/vmw_vsock/virtio_transport.c
@@ -94,6 +94,63 @@ static u32 virtio_transport_get_local_cid(void)
return ret;
}
+/* Caller need to hold vsock->tx_lock on vq */
+static int virtio_transport_send_skb(struct sk_buff *skb, struct virtqueue *vq,
+ struct virtio_vsock *vsock)
+{
+ int ret, in_sg = 0, out_sg = 0;
+ struct scatterlist **sgs;
+
+ sgs = vsock->out_sgs;
+ sg_init_one(sgs[out_sg], virtio_vsock_hdr(skb),
+ sizeof(*virtio_vsock_hdr(skb)));
+ out_sg++;
+
+ if (!skb_is_nonlinear(skb)) {
+ if (skb->len > 0) {
+ sg_init_one(sgs[out_sg], skb->data, skb->len);
+ out_sg++;
+ }
+ } else {
+ struct skb_shared_info *si;
+ int i;
+
+ /* If skb is nonlinear, then its buffer must contain
+ * only header and nothing more. Data is stored in
+ * the fragged part.
+ */
+ WARN_ON_ONCE(skb_headroom(skb) != sizeof(*virtio_vsock_hdr(skb)));
+
+ si = skb_shinfo(skb);
+
+ for (i = 0; i < si->nr_frags; i++) {
+ skb_frag_t *skb_frag = &si->frags[i];
+ void *va;
+
+ /* We will use 'page_to_virt()' for the userspace page
+ * here, because virtio or dma-mapping layers will call
+ * 'virt_to_phys()' later to fill the buffer descriptor.
+ * We don't touch memory at "virtual" address of this page.
+ */
+ va = page_to_virt(skb_frag_page(skb_frag));
+ sg_init_one(sgs[out_sg],
+ va + skb_frag_off(skb_frag),
+ skb_frag_size(skb_frag));
+ out_sg++;
+ }
+ }
+
+ ret = virtqueue_add_sgs(vq, sgs, out_sg, in_sg, skb, GFP_KERNEL);
+ /* Usually this means that there is no more space available in
+ * the vq
+ */
+ if (ret < 0)
+ return ret;
+
+ virtio_transport_deliver_tap_pkt(skb);
+ return 0;
+}
+
static void
virtio_transport_send_pkt_work(struct work_struct *work)
{
@@ -111,66 +168,22 @@ virtio_transport_send_pkt_work(struct work_struct *work)
vq = vsock->vqs[VSOCK_VQ_TX];
for (;;) {
- int ret, in_sg = 0, out_sg = 0;
- struct scatterlist **sgs;
struct sk_buff *skb;
bool reply;
+ int ret;
skb = virtio_vsock_skb_dequeue(&vsock->send_pkt_queue);
if (!skb)
break;
reply = virtio_vsock_skb_reply(skb);
- sgs = vsock->out_sgs;
- sg_init_one(sgs[out_sg], virtio_vsock_hdr(skb),
- sizeof(*virtio_vsock_hdr(skb)));
- out_sg++;
-
- if (!skb_is_nonlinear(skb)) {
- if (skb->len > 0) {
- sg_init_one(sgs[out_sg], skb->data, skb->len);
- out_sg++;
- }
- } else {
- struct skb_shared_info *si;
- int i;
-
- /* If skb is nonlinear, then its buffer must contain
- * only header and nothing more. Data is stored in
- * the fragged part.
- */
- WARN_ON_ONCE(skb_headroom(skb) != sizeof(*virtio_vsock_hdr(skb)));
-
- si = skb_shinfo(skb);
- for (i = 0; i < si->nr_frags; i++) {
- skb_frag_t *skb_frag = &si->frags[i];
- void *va;
-
- /* We will use 'page_to_virt()' for the userspace page
- * here, because virtio or dma-mapping layers will call
- * 'virt_to_phys()' later to fill the buffer descriptor.
- * We don't touch memory at "virtual" address of this page.
- */
- va = page_to_virt(skb_frag_page(skb_frag));
- sg_init_one(sgs[out_sg],
- va + skb_frag_off(skb_frag),
- skb_frag_size(skb_frag));
- out_sg++;
- }
- }
-
- ret = virtqueue_add_sgs(vq, sgs, out_sg, in_sg, skb, GFP_KERNEL);
- /* Usually this means that there is no more space available in
- * the vq
- */
+ ret = virtio_transport_send_skb(skb, vq, vsock);
if (ret < 0) {
virtio_vsock_skb_queue_head(&vsock->send_pkt_queue, skb);
break;
}
- virtio_transport_deliver_tap_pkt(skb);
-
if (reply) {
struct virtqueue *rx_vq = vsock->vqs[VSOCK_VQ_RX];
int val;
--
2.45.2[PATCH net-next v4 2/2] vsock/virtio: avoid queuing packets when intermediate queue is empty
中間キューが空 & virtqueue に空きがある & パケットを送信している他のプロセスがない (tx_lock が保持されている) 場合に、中間キューをバイパスする処理を追加します。
diff --git a/net/vmw_vsock/virtio_transport.c b/net/vmw_vsock/virtio_transport.c
index f641e906f351..f992f9a216f0 100644
--- a/net/vmw_vsock/virtio_transport.c
+++ b/net/vmw_vsock/virtio_transport.c
@@ -208,6 +208,28 @@ virtio_transport_send_pkt_work(struct work_struct *work)
queue_work(virtio_vsock_workqueue, &vsock->rx_work);
}
+/* Caller need to hold RCU for vsock.
+ * Returns 0 if the packet is successfully put on the vq.
+ */
+static int virtio_transport_send_skb_fast_path(struct virtio_vsock *vsock, struct sk_buff *skb)
+{
+ struct virtqueue *vq = vsock->vqs[VSOCK_VQ_TX];
+ int ret;
+
+ /* Inside RCU, can't sleep! */
+ ret = mutex_trylock(&vsock->tx_lock);
+ if (unlikely(ret == 0))
+ return -EBUSY;
+
+ ret = virtio_transport_send_skb(skb, vq, vsock);
+ if (ret == 0)
+ virtqueue_kick(vq);
+
+ mutex_unlock(&vsock->tx_lock);
+
+ return ret;
+}
+
static int
virtio_transport_send_pkt(struct sk_buff *skb)
{
@@ -231,11 +253,20 @@ virtio_transport_send_pkt(struct sk_buff *skb)
goto out_rcu;
}
- if (virtio_vsock_skb_reply(skb))
- atomic_inc(&vsock->queued_replies);
+ /* If send_pkt_queue is empty, we can safely bypass this queue
+ * because packet order is maintained and (try) to put the packet
+ * on the virtqueue using virtio_transport_send_skb_fast_path.
+ * If this fails we simply put the packet on the intermediate
+ * queue and schedule the worker.
+ */
+ if (!skb_queue_empty_lockless(&vsock->send_pkt_queue) ||
+ virtio_transport_send_skb_fast_path(vsock, skb)) {
+ if (virtio_vsock_skb_reply(skb))
+ atomic_inc(&vsock->queued_replies);
- virtio_vsock_skb_queue_tail(&vsock->send_pkt_queue, skb);
- queue_work(virtio_vsock_workqueue, &vsock->send_pkt_work);
+ virtio_vsock_skb_queue_tail(&vsock->send_pkt_queue, skb);
+ queue_work(virtio_vsock_workqueue, &vsock->send_pkt_work);
+ }
out_rcu:
rcu_read_unlock();
--
2.45.246: skb_queue_empty_lockless() で中間キューが empty かつ lockless なのを確認します。
47: 確認できた場合、virtio_transport_send_skb_fast_path() を呼び出して1一つ前のパッチで切り出した virtio_transport_send_skb() を実行することで中間キューをバイパスします。
53,54: 中間キューにデータが入ってる or 他プロセスによってロック済の場合、送信の順番を保つために従来どおり中間キューを利用します。
性能評価
コミットメッセージに載せられていたベンチマーク結果を整形して記載します。
中間キューのバイパスということでレイテンシ改善が主な部分かと思っていたのですが、スループットも30~70%改善されているようです。
テスト環境は、Intel i7-10700KF CPU @ 3.80GHz を搭載したホスト上で QEMU/KVM (vhost プロセス使用) を使い、すべての vCPU を pCPU に個別にピン留め(CPU割り当て)した L1 ゲストを動かしています。
レイテンシ計測
ツール:Fio ver3.37-56
モード: pingpong (h-g-h)
テスト回数: 50
テストごとの実行時間: 50秒
ソケットタイプ: SOCK_STREAM
fio ベンチマークでは、ホストOSがゲストVMへペイロードを送り、同じペイロードを受け取る(エコーバック)テストを行っています。fio プロセスはホストとゲストの両方で CPU ピン留めされています。
スループット計測
ツール: iperf-vsock
オプション:
-l (バッファ長) … 4K / 64K / 128K
-P (並列ストリーム数) … 1, 2, 4
レイテンシ改善
ペイロード 64B
| Version | 1st perc. | overall | 99th perc. |
|---|---|---|---|
| Linux 6.9.8 | 12.91 | 16.78 | 42.24 |
| Linux 6.11 | 9.77 | 13.57 | 39.17 |
ペイロード 512B
| Version | 1st perc. | overall | 99th perc. |
|---|---|---|---|
| Linux 6.9.8 | 13.35 | 17.35 | 41.52 |
| Linux 6.11 | 10.25 | 14.11 | 39.58 |
ペイロード 4KB
| Version | 1st perc. | overall | 99th perc. |
|---|---|---|---|
| Linux 6.9.8 | 14.71 | 19.87 | 41.52 |
| Linux 6.11 | 10.51 | 14.96 | 40.81 |
スループット改善
ペイロードサイズ 4K / 64K / 128K でストリーム数 (並列数) を変更します。
ストリーム数 1 (P=1)
| Version | 4K | 64K | 128K |
|---|---|---|---|
| Linux 6.9.8 | 6.87 | 29.3 | 29.5 |
| Linux 6.11 | 10.5 | 39.4 | 39.9 |
| 性能向上率 | +52.8% | +34.5% | +35.3% |
ストリーム数 2 (P=2)
| Version | 4K | 64K | 128K |
|---|---|---|---|
| Linux 6.9.8 | 10.5 | 32.8 | 33.2 |
| Linux 6.11 | 17.8 | 47.7 | 48.5 |
| 性能向上率 | +69.5% | +45.4% | +46.1% |
ストリーム数 4 (P=4)
| Version | 4K | 64K | 128K |
|---|---|---|---|
| Linux 6.9.8 | 12.7 | 33.6 | 34.2 |
| Linux 6.11 | 16.9 | 48.1 | 50.5 |
| 性能向上率 | +33.1% | +43.2% | +47.7% |
参考サイト
- “VirtIO Vsock Performance To Improve With Linux 6.12”, Phoronix
- “libkrunでのネットワーク通信”, 赤帽エンジニアブログ
- [PATCH net-next v4 0/2] vsock: avoid queuing on intermediate queue if possible
- C言語の || は左から順番に評価が行われ、一つでも True になったら後続の評価をすっ飛ばします。後続が True だろうと False だろうと評価にはもう関係ないからです。 ↩︎