今回はIntel SDMをはじめとした数千枚のPDF仕様書をRAGとして作成し、それをMCP経由でClineに使わせることでAIエージェントのプログラミング能力を強化する方法を紹介します。
珍しくAIのお話です。
目次
背景
趣味で自作OSをやっているのですが、Intelのx86仕様書(通称SDM/Software Developer Manual)やUEFIの仕様書、RISC-Vの仕様書が複雑すぎて読むのが大変です。
最近はDeepResearchを活用したり、o3-mini-highなんかは普通に優秀なので聞けば返答を貰えることも多いですが、エディタとブラウザを行き来して、いちいちコードや実行結果をコピペするのも面倒です。
そういった環境でClineやCursorなどのAIエージェントが登場し、これを自作OS開発に活用したいと思ったのですが…いかんせんAPI料金が高い🥲
Geminiの無料枠でなんとか頑張ろうとしていますが、性能や知識量がどうしてもo3-mini-highやClaude 3.7と比べて劣る。特に自作OSは独創性より仕様に則って作るのが大事なので、ハルシネーションを可能な限り避けたい。
そういったタイミングで最近のプログラミングAIエージェント+MCPの流行を見て、これってIntelの仕様書を読ませたRAGにMCPを喋らせれば良いんじゃね?って思ったのがきっかけです。
実装
概要
大雑把なイメージです。
AIに詳しいわけではないので、理解が間違ってるかもしれません。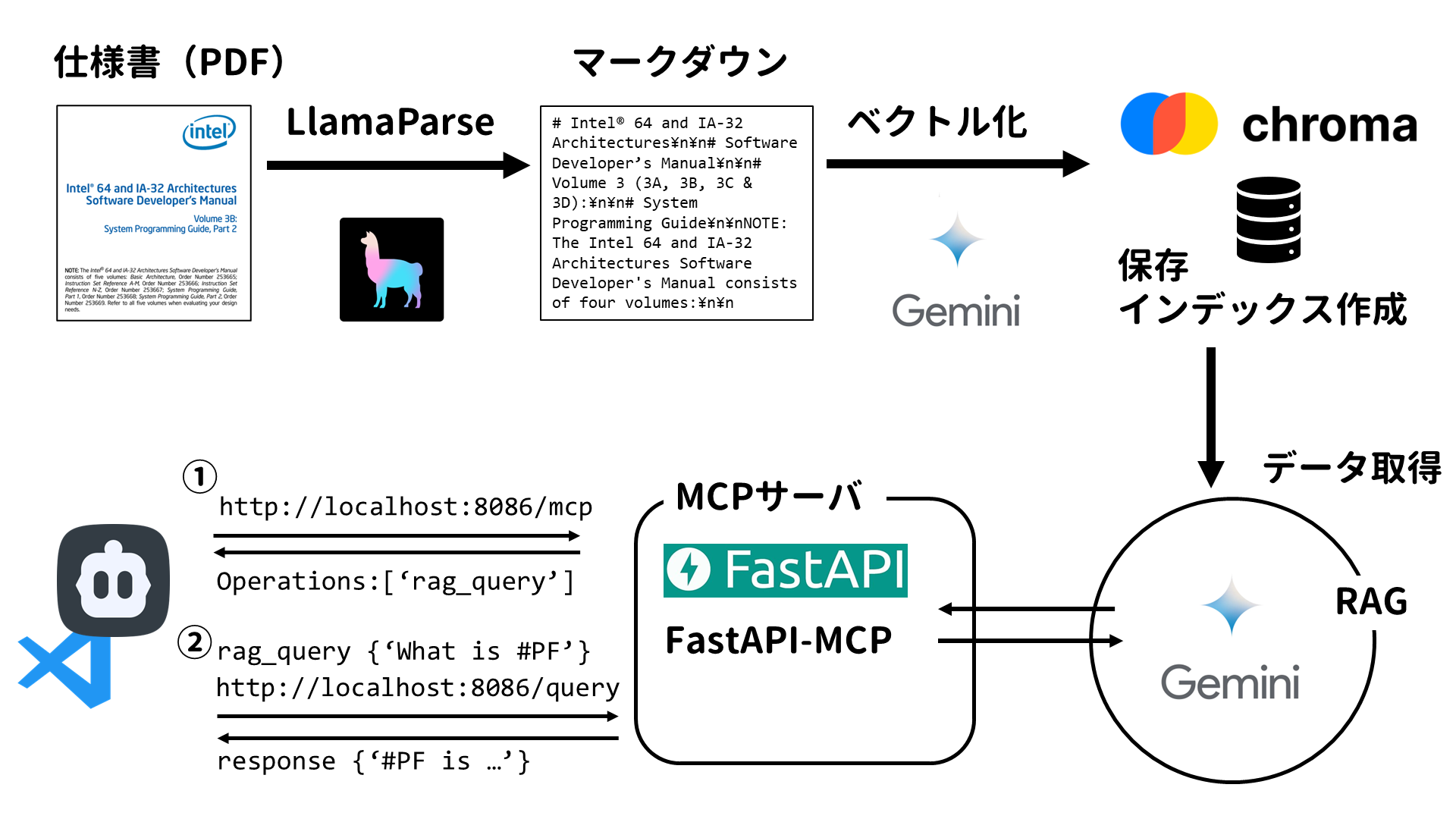
準備
pipで必要なパッケージをインストールします。venvの利用を強く推奨します。
# LlamaIndexコアライブラリ
pip install llama-index
# LlamaParse PDFパーサー用
pip install llama-parse
# ChromaDBベクトルストア用
pip install llama-index-vector-stores-chroma chromadb
# Google Generative AI LLM連携用
pip install llama-index-llms-google-genai
# Google Generative AI Embedding連携用
pip install llama-index-embeddings-google-genai
# APIサーバー用
pip install fastapi uvicorn fastapi-mcp sse-starlette
# 環境変数管理用
pip install python-dotenv google-cloud-aiplatformPDFの仕様書をLlamaParseでマークダウンに変換する
まずPDFのままではお話にならないので、テキストに変換する必要があります。
今回は LlamaCloud の LlamaParse を利用します。
Llama Cloud API keyの発行
公式サイトに登録 & ログインします。
https://cloud.llamaindex.ai
左側の API Keys から API key を発行します。
ちなみにこの画面でも、ParseからPDFを投げることができます。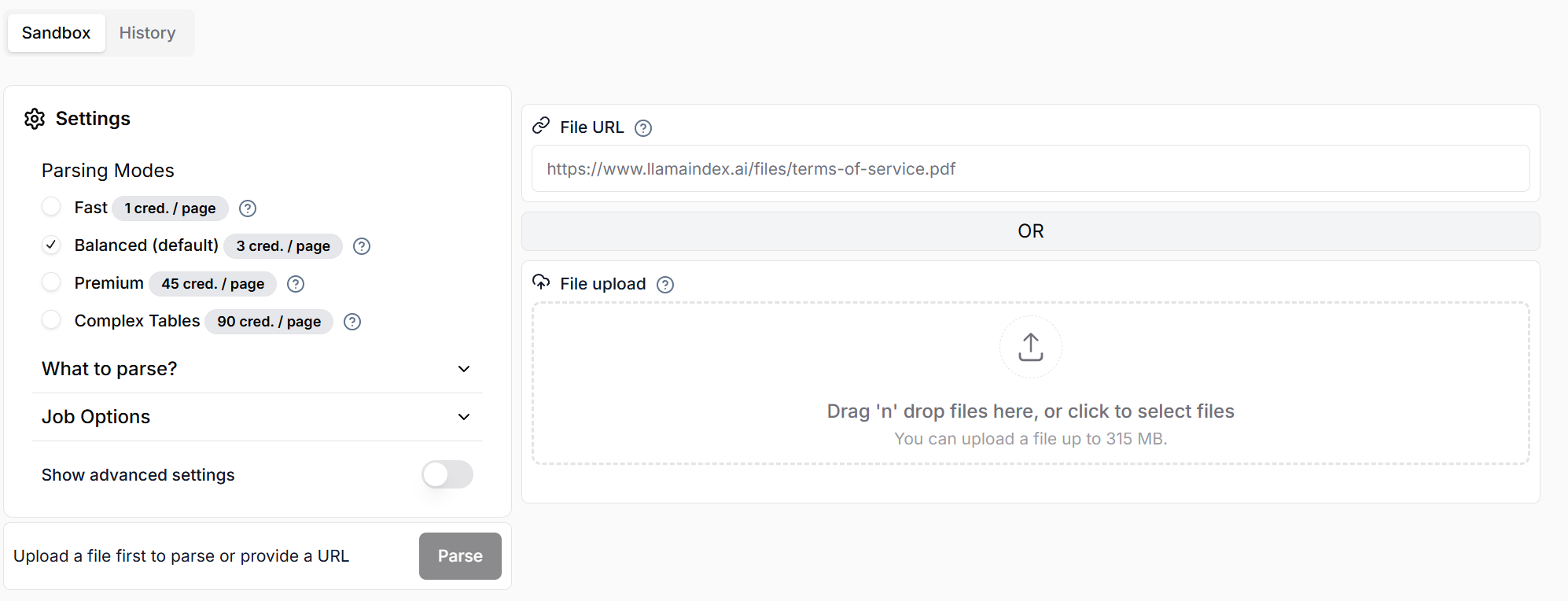
ただし単価には注意。無料枠は10000クレジット/月です。
Fast はテキストのみで、複雑な表や画像を含む場合は Premium/Complex Tables が良いですがクレジット消費量も多い。今回は複雑な表を含みますがPDFが数千枚もあるのでデフォルトのBalancedで行きます。
Pythonスクリプト
API Keyを使ってPDFをマークダウン化します。
from llama_parse import LlamaParse
import os
from dotenv import load_dotenv
load_dotenv() #.envファイルから環境変数を読み込む
# LlamaParseを使用してPDFファイルを解析する
parser = LlamaParse(
api_key=os.getenv("LLAMA_CLOUD_API_KEY"),
result_type="markdown", # Markdown形式でテーブル構造を保持
verbose=True
)
pdf_paths = ["./doc/intel-sdm-vol-3abcd.pdf"] # 必要に応じて複数のPDFを追加
documents = parser.load_data(pdf_paths)
print(f"Parsed {len(documents)} documents from {len(pdf_paths)} PDF files.")もしweb上から実行していたり、再実行したい場合はjob_idから実行結果を取得できます。
https://docs.cloud.llamaindex.ai/llamaparse/parsing/output_modes
from llama_index.core.schema import Document
import requests
# job_idを指定してLlamaParseの結果を取得する
job_id = "XXXXX"
api_url = f"https://api.cloud.llamaindex.ai/api/v1/parsing/job/{job_id}/result/markdown"
api_key = os.getenv("LLAMA_CLOUD_API_KEY")
headers = {
"accept": "application/json",
"Authorization": f"Bearer {api_key}"
}
response = requests.get(api_url, headers=headers)
response.raise_for_status()
documents = [Document(text=response.text, metadata={"job_id": job_id})]
print(f"Parsed {len(documents)} documents from LlamaParse job ID: {job_id}.")マークダウンをGemini Embeddingでベクトルに変換する
RAGとして使えるようにベクトル化します。ここではGeminiを利用します(いつも無料枠ありがとう)
# MarkdownElementNodeParserを使用する
from llama_index.core.node_parser import MarkdownElementNodeParser
from llama_index.core import Settings
Settings.llm = None # マークダウンのパースにLLMは不要
node_parser = MarkdownElementNodeParser(llm=None, num_workers=os.cpu_count())
nodes = node_parser.get_nodes_from_documents(documents)
print(f"Split documents into {len(nodes)} nodes.")
# Gemini Embeddingを使用する
from llama_index.embeddings.google_genai import GoogleGenAIEmbedding
# Settingsオブジェクト経由でグローバルに設定
Settings.embed_model = GoogleGenAIEmbedding(
model_name="text-embedding-004", # または他の利用可能なGemini埋め込みモデル
api_key=os.getenv("GOOGLE_API_KEY"),
)
print(f"Using embedding model: {Settings.embed_model.model_name}")利用できる最新モデルはGeminiのドキュメントを参照してください。
https://ai.google.dev/gemini-api/docs/models?hl=ja#text-embedding
ベクトルをChromaDBに保存
ChromaDBはベクトル埋め込みを格納し、LLMアプリケーションを開発・構築するために設計されたオープンソースのベクトルデータベースです。
import chromadb
from llama_index.vector_stores.chroma import ChromaVectorStore
from llama_index.core import VectorStoreIndex, StorageContext
db_path = "./chroma_db_specs_gemini"
collection_name = "intel_sdm3_specs_gemini"
db = chromadb.PersistentClient(path=db_path)
try:
chroma_collection = db.get_collection(collection_name)
print(f"Using existing Chroma collection: {collection_name}")
except:
chroma_collection = db.create_collection(collection_name)
print(f"Created new Chroma collection: {collection_name}")
vector_store = ChromaVectorStore(chroma_collection=chroma_collection)
storage_context = StorageContext.from_defaults(vector_store=vector_store)
# インデックスの構築と永続化 (EmbeddingはSettings.embed_modelから自動で使用される)
index = VectorStoreIndex(
nodes,
storage_context=storage_context,
show_progress=True
)
print(f"Index created/updated and persisted at {db_path}")RAGの動作テスト
一旦この時点で正しく動作しているか確認します。
from llama_index.core import load_index_from_storage, StorageContext, Settings, VectorStoreIndex
from llama_index.vector_stores.chroma import ChromaVectorStore
from llama_index.llms.google_genai import GoogleGenAI
from llama_index.embeddings.google_genai import GoogleGenAIEmbedding
import chromadb
import os
from dotenv import load_dotenv
load_dotenv()
# LLM設定 (Google Generative AI)
Settings.llm = GoogleGenAI(
model_name="gemini-2.0-flash", # または他の利用可能なGemini LLMモデル
api_key=os.getenv("GOOGLE_API_KEY")
)
print(f"Using LLM: {Settings.llm.metadata.model_name}")
# Embeddingモデル設定 (Google Generative AI)
Settings.embed_model = GoogleGenAIEmbedding(
model_name="models/text-embedding-004", # または他の利用可能なGemini埋め込みモデル
api_key=os.getenv("GOOGLE_API_KEY")
)
print(f"Using embedding model: {Settings.embed_model.model_name}")
# ChromaDBからインデックスをロード
db_path = "./chroma_db_specs_gemini"
collection_name = "intel_sdm3_specs_gemini"
db = chromadb.PersistentClient(path=db_path)
chroma_collection = db.get_collection(collection_name)
vector_store = ChromaVectorStore(chroma_collection=chroma_collection)
# Settingsからembed_modelを渡す必要がある場合がある
storage_context = StorageContext.from_defaults(vector_store=vector_store)
index = VectorStoreIndex.from_vector_store(vector_store, embed_model=Settings.embed_model)
print(f"Loaded index from {db_path}")
# クエリエンジンの作成 (Settings.llm を使用)
query_engine = index.as_query_engine(
similarity_top_k=5, # 上位5件のチャンクを取得
llm=Settings.llm # グローバル設定のLLMを使用
)
print("Query engine created.")
# クエリ
query_str = "#PFのエラーコードの各ビットの意味を教えてください。"
print(f"\nQuerying: {query_str}")
response = query_engine.query(query_str)
print("\nAnswer:")
print(response)実行してみるとこんな感じ。
Using LLM: gemini-2.0-flash
Using embedding model: models/text-embedding-004
Loaded index from ./chroma_db_specs_gemini
Query engine created.
Querying: #PFのエラーコードの各ビットの意味を教えてください。
Answer:
ページフォルトのエラーコードの各ビットの意味は次のとおりです。
* ビット0 (P): このフラグは、リニアアドレスの変換が存在しない場合に0になります。これは、Pフラグが、そのアドレスの変換に使用されるページング構造エントリのいずれかで0であったためです。
* ビット1 (W/R): ページフォルト例外を引き起こしたアクセスが書き込みであった場合、このフラグは1になります。それ以外の場合は0です。
* ビット2 (U/S): ユーザーモードアクセスがページフォルト例外を引き起こした場合、このフラグは1になります。スーパーバイザーモードアクセスがそうであった場合は0です。
* ビット3 (RSVD): このフラグは、リニアアドレスの変換が存在しない場合に1になります。これは、予約済みビットが、そのアドレスの変換に使用されるページング構造エントリのいずれかで設定されていたためです。
* ビット4 (I/D): このフラグは、(1)ページフォルト例外を引き起こしたアクセスが命令フェッチであった場合、および(2)CR4.SMEP = 1であるか、(i)CR4.PAE = 1(PAEページングまたは4レベルページングが使用中)および(ii)IA32\_EFER.NXE = 1の両方である場合に1になります。それ以外の場合、フラグは0です。
* ビット5 (PK): このフラグは、(1)IA32\_EFER.LMA = CR4.PKE = 1である場合、(2)ページフォルト例外を引き起こしたアクセスがデータアクセスであった場合、(3)リニアアドレスが保護キーiを持つユーザーモードアドレスであった場合、および(5)PKRUレジスタが、(a)ADi = 1であるか、(b)次のすべてが保持されるようなものである場合に1になります。(i)WDi = 1、(ii)アクセスが書き込みアクセスである、および(iii)CR0.WP = 1であるか、ページフォルト例外を引き起こしたアクセスがユーザーモードアクセスであったかのいずれかです。
* ビット15 (SGX): このフラグは、例外がページングとは無関係であり、SGX固有のアクセス制御要件の違反に起因する場合に1になります。FastAPI + FastAPI_MCPでMCPサーバを作る
FastAPIを利用してクエリをPOSTで受け取るエンドポイントを作成します。
FastAPI_MCPを利用してFastAPIサーバをMCPサーバ化します
https://pypi.org/project/fastapi-mcp/
https://huggingface.co/blog/lynn-mikami/fastapi-mcp-server
from fastapi import FastAPI, HTTPException
from fastapi_mcp import FastApiMCP
from pydantic import BaseModel
import uvicorn
import os
from dotenv import load_dotenv
from contextlib import asynccontextmanager
from llama_index.core import Settings, VectorStoreIndex
from llama_index.vector_stores.chroma import ChromaVectorStore
from llama_index.llms.google_genai import GoogleGenAI
from llama_index.embeddings.google_genai import GoogleGenAIEmbedding
import chromadb
load_dotenv() #.envファイルからAPIキーを読み込む
# グローバル変数ではなく、lifespan内で管理する辞書を使用
rag_pipeline = {}
# --- lifespanコンテキストマネージャー ---
@asynccontextmanager
async def lifespan(app: FastAPI):
# アプリケーション起動時に実行されるコード
print("Loading RAG pipeline...")
try:
# --- LlamaIndex初期化コード (Gemini + Google Embedding + ChromaDB) ---
db_path = "./chroma_db_specs_gemini"
collection_name = "intel_sdm3_specs_gemini"
if not os.getenv("GOOGLE_API_KEY"):
raise ValueError("GOOGLE_API_KEY environment variable not set.")
# ここでLLMとEmbeddingを明示的に設定
Settings.llm = GoogleGenAI(
model_name="gemini-2.0-flash",
api_key=os.getenv("GOOGLE_API_KEY")
)
Settings.embed_model = GoogleGenAIEmbedding(
model_name="models/text-embedding-004",
api_key=os.getenv("GOOGLE_API_KEY")
)
print(f"Using LLM: {Settings.embed_model.model_name}")
print(f"Using embedding model: {Settings.embed_model.model_name}")
db = chromadb.PersistentClient(path=db_path)
chroma_collection = db.get_collection(collection_name)
vector_store = ChromaVectorStore(chroma_collection=chroma_collection)
index = VectorStoreIndex.from_vector_store(
vector_store=vector_store,
embed_model=Settings.embed_model
)
query_engine = index.as_query_engine(similarity_top_k=5, llm=Settings.llm)
rag_pipeline["query_engine"] = query_engine # lifespan内で管理
print("Query engine initialized successfully.")
except Exception as e:
print(f"Error initializing query engine: {e}")
rag_pipeline["query_engine"] = None # エラー時はNoneを設定
yield # アプリケーションが実行される
# アプリケーション終了時に実行されるコード (クリーンアップなど)
print("Shutting down RAG pipeline...")
rag_pipeline.clear()
# ------------------------------------
# FastAPIアプリの初期化時にlifespanを指定
app = FastAPI(title="Specification QA API with Gemini", lifespan=lifespan)
# FastAPIアプリをMCPサーバ化
mcp = FastApiMCP(
app,
name="SpecificationQA-MCP",
description="RAG 質問応答用 MCP サーバ",
base_url="http://localhost:8086",
describe_all_responses=True,
describe_full_response_schema=True,
include_operations=["rag_query"], # 実行可能なオペレーション
)
mcp.mount() # /mcp/sse と /mcp/messages を自動生成
class QueryRequest(BaseModel):
query: str
class QueryResponse(BaseModel):
answer: str
@app.post("/query", response_model=QueryResponse, operation_id="rag_query")
async def handle_query(request: QueryRequest):
query_engine = rag_pipeline.get("query_engine") # lifespanから取得
if query_engine is None:
raise HTTPException(status_code=503, detail="Query engine is not available.")
print(f"Received query: {request.query}")
try:
# 非同期対応のクエリメソッドを使用 (aquery)
response = await query_engine.aquery(request.query)
answer_text = str(response)
print(f"Generated answer: {answer_text[:100]}...") # 最初の100文字をログ出力
return QueryResponse(answer=answer_text)
except Exception as e:
print(f"Error during query processing: {e}")
raise HTTPException(status_code=500, detail=f"Error processing query: {e}")
if __name__ == "__main__":
# uvicorn main_gemini:app --reload --port 8086
mcp.setup_server()
uvicorn.run(app, host="0.0.0.0", port=8086)MCPサーバの実行可能なオペレーションとしてrag_queryを指定し、FastAPIのエンドポイントと紐つけます。
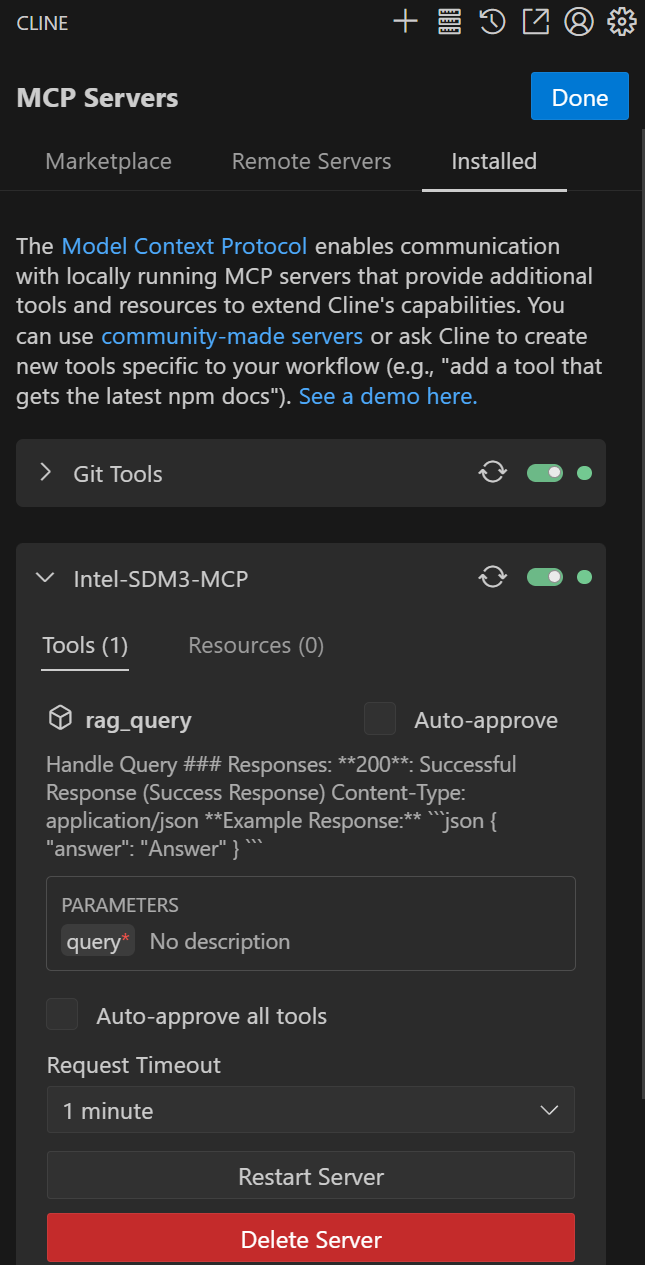
VSCodeのClineでMCPサーバの設定をする
cline_mcp_settings.json に追加します。
{
"mcpServers": {
"Intel-SDM3-MCP": {
"type": "sse",
"url": "http://localhost:8086/mcp",
"disabled": false,
"autoApprove": [],
"operations": [
"rag_query"
]
}
}
}
ClineからMCPサーバを利用してみる
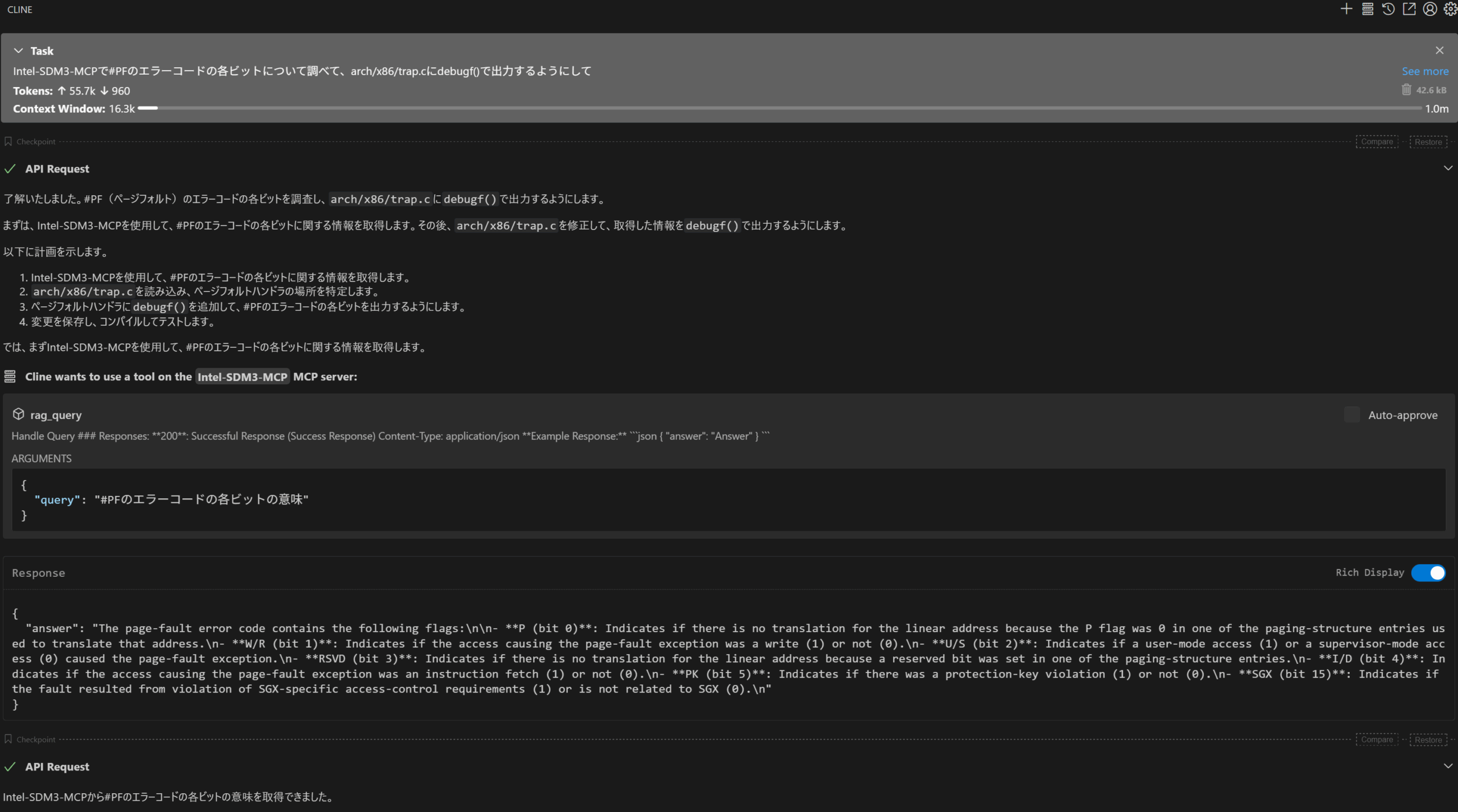
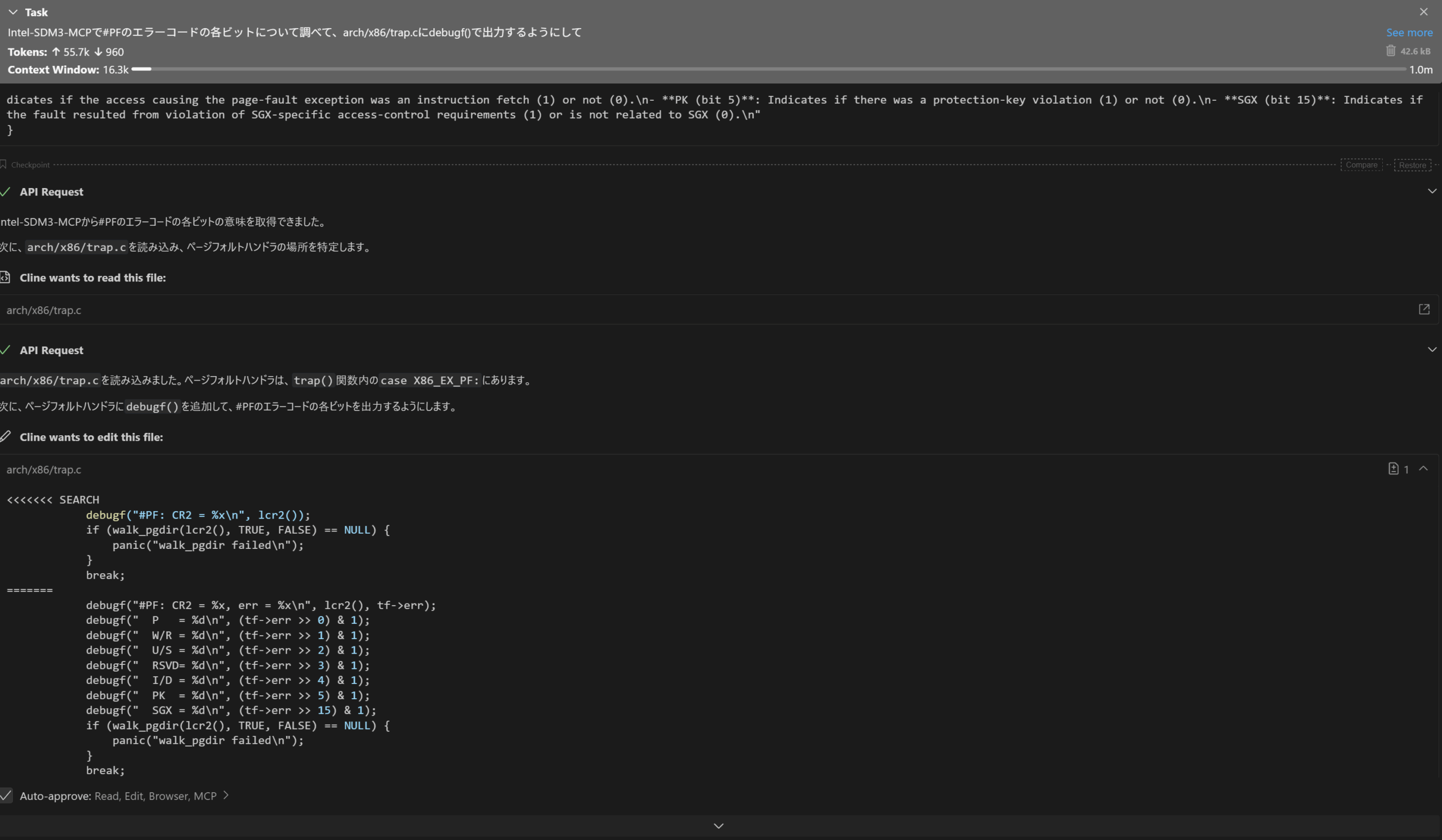
いい感じですね。
無料枠のクレジットが回復したらUEFIの仕様書とかRISC-Vの仕様書も食わせてみようと思います。